2.2.20
【ベンチマーク】高次元疎データの分類
まとめ
- サンプル数200に対して特徴量500(うち有用20)の高次元疎データで6つの分類器 × 4つの前処理を比較する。
- L1正則化やSelectKBestによる特徴選択が精度を大きく改善する。
- RBF-SVMは次元削減なしだと過学習し、ナイーブベイズは高次元でも安定する。
テキスト分類・遺伝子発現データ・アンケートの自由記述など、特徴量がサンプル数を超えるデータセットは実務で珍しくない。こうした高次元疎データでは、モデルの選択以上に前処理(特徴選択・次元削減)が精度を左右する。
1. データの特徴 #
n=200サンプル、p=500特徴量、3クラス分類- 有用な特徴量は20個だけ。残り480個はノイズ
- 次元の呪い:特徴空間が広すぎて、距離ベースの手法は機能しにくい
2. 合成データの生成 #
| |
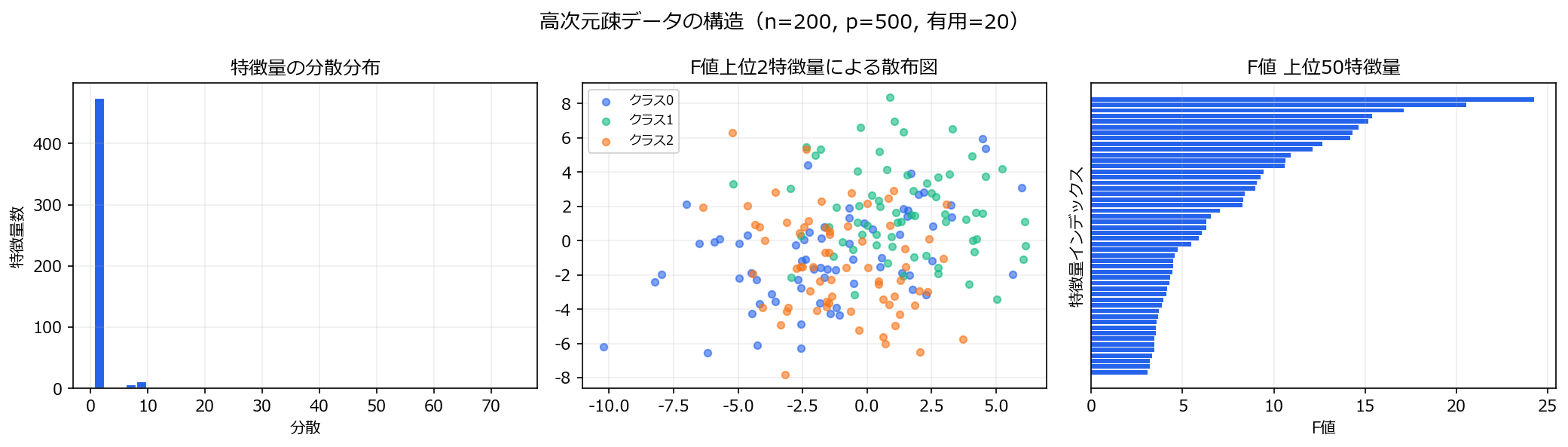
3. 比較するパイプライン #
| 前処理 | 分類器 |
|---|---|
| なし | Logistic(L1), Logistic(L2), SVM(linear), SVM(RBF), NaiveBayes, RandomForest |
| VarianceThreshold (中央値以上) | 同上 |
| SelectKBest (k=50) | 同上 |
| PCA (n=50) | 同上 |
合計: 4前処理 × 6分類器 = 24パイプライン
4. 実験と結果 #
| |
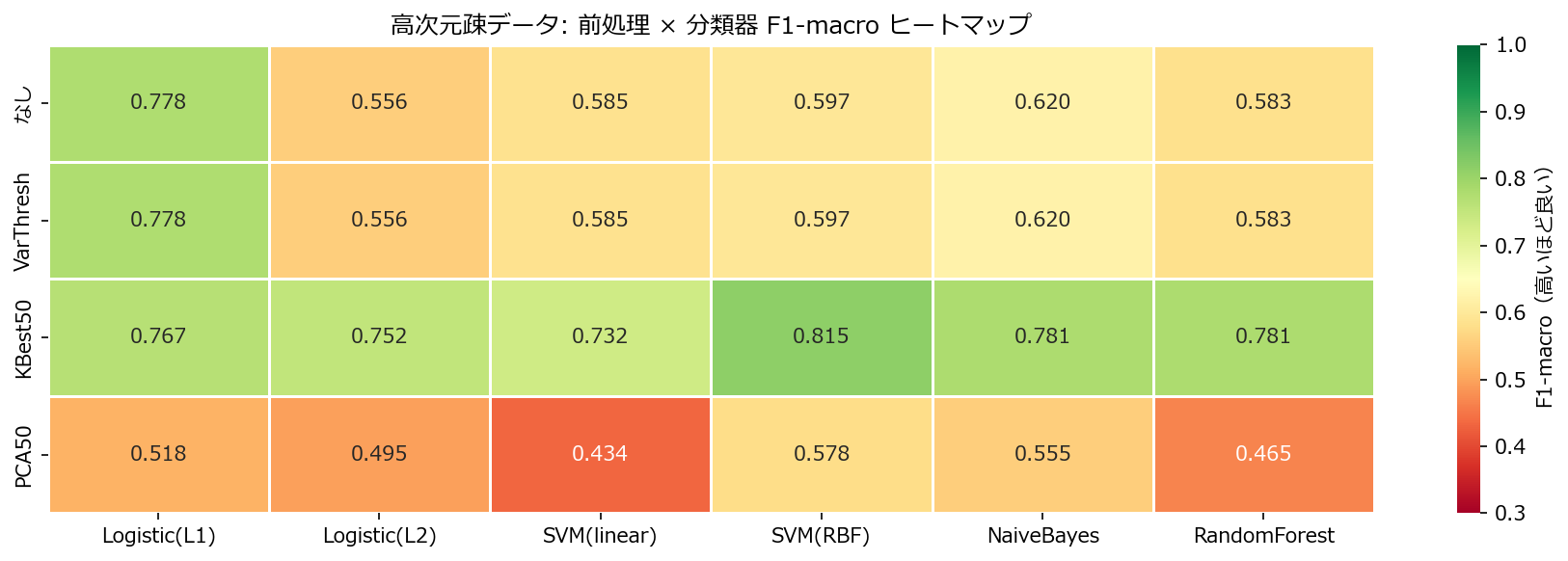
読み方のポイント #
- SelectKBest(k=50)やPCA(n=50)で次元を絞ると、ほぼすべての分類器で精度が改善する。
- L1正則化のLogisticは前処理なしでも比較的健闘する。内部的にスパースな特徴選択を行っているため。
- RBF-SVMは前処理なしだとF1が大幅に低下する。高次元空間ではRBFカーネルの距離計算が機能しにくい。
- ナイーブベイズは前処理によらず安定。独立性仮定がノイズ特徴量を無視する効果を生む。
5. 誤差パターン分析 #
| |
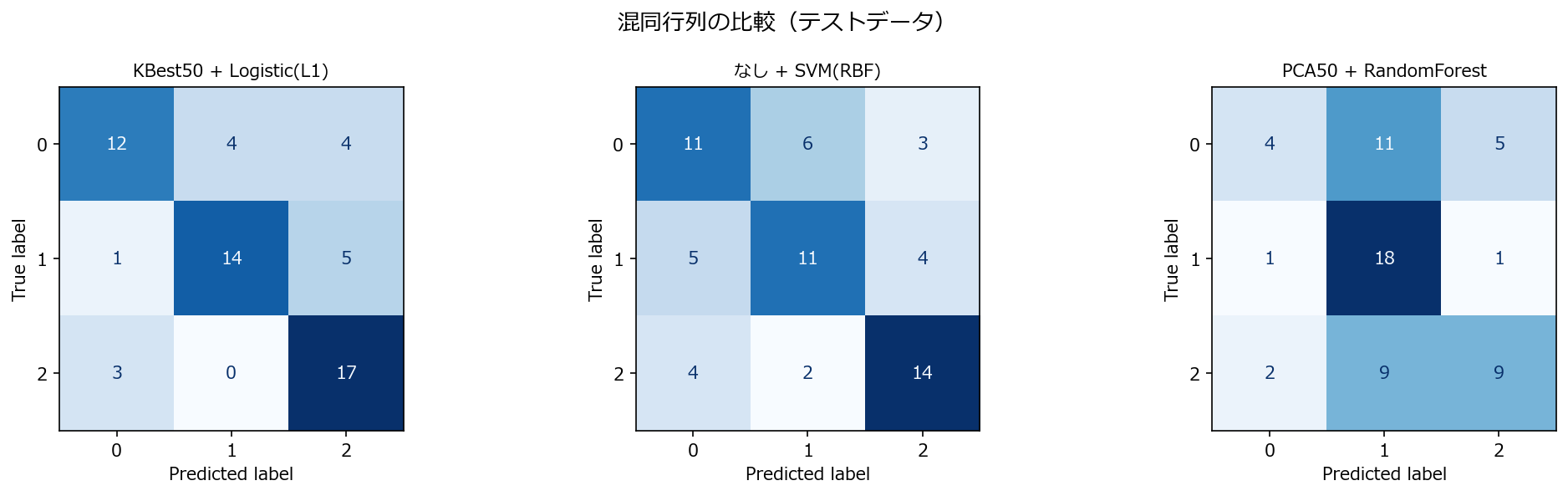
前処理なしのRBF-SVMはオフダイアゴナル(誤分類)が多く、特にクラス間の混同が激しい。KBest+L1 Logisticは対角成分が支配的で、3クラスとも安定して分類できている。
6. よくある失敗パターン #
- 前処理なしでRBFカーネルを使う: 高次元空間ではすべてのサンプル間距離がほぼ等しくなり、カーネルが効かない。線形カーネルか次元削減を先に行う。
- 全特徴量でランダムフォレストを使う: 動きはするが、ノイズ特徴量がスプリット候補に入るため精度が落ちる。
max_featuresを小さく設定するか、事前に特徴選択する。