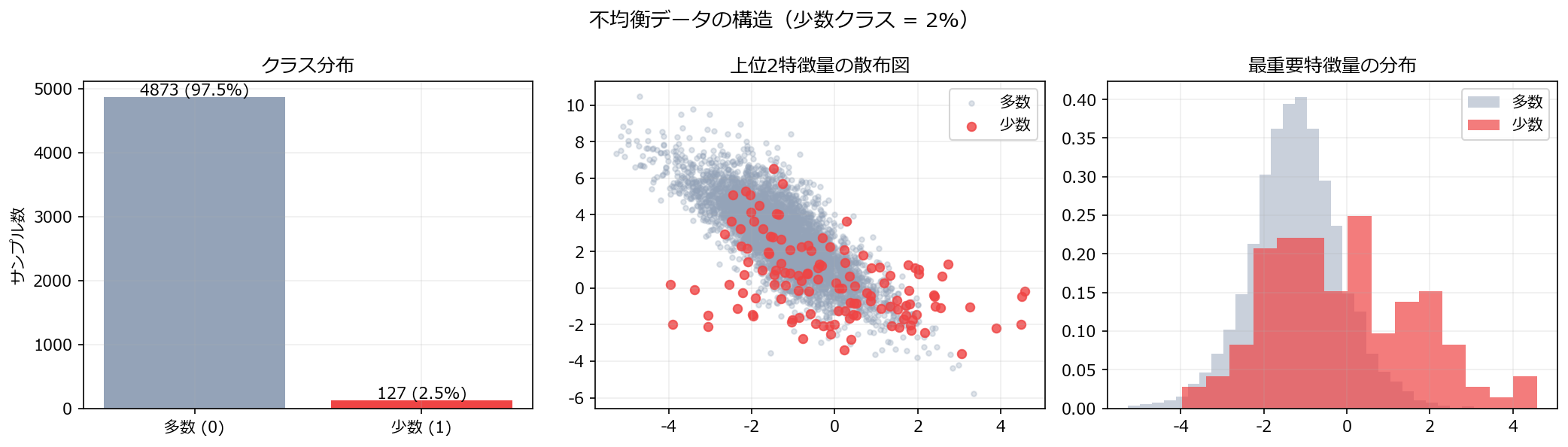
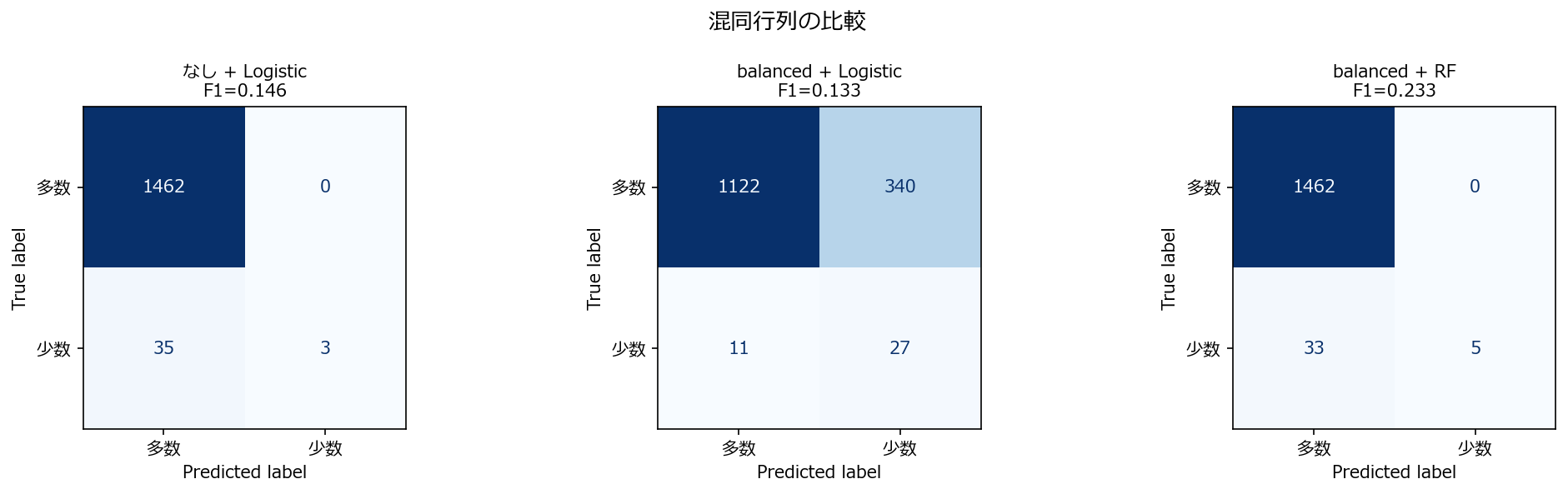
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
| from sklearn.model_selection import cross_val_score, StratifiedKFold
from sklearn.preprocessing import StandardScaler
from sklearn.pipeline import Pipeline
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import make_scorer, f1_score, average_precision_score, matthews_corrcoef
import seaborn as sns
cv = StratifiedKFold(n_splits=5, shuffle=True, random_state=42)
def random_oversample(X_train, y_train, random_state=42):
"""少数クラスを多数クラスと同数になるまで複製する。"""
rng = np.random.default_rng(random_state)
minority = X_train[y_train == 1]
minority_y = y_train[y_train == 1]
n_to_add = (y_train == 0).sum() - len(minority)
if n_to_add <= 0:
return X_train, y_train
idx = rng.choice(len(minority), size=n_to_add, replace=True)
X_aug = np.vstack([X_train, minority[idx]])
y_aug = np.concatenate([y_train, minority_y[idx]])
return X_aug, y_aug
classifiers_default = {
"Logistic": LogisticRegression(max_iter=1000, random_state=42),
"SVM": SVC(random_state=42),
"KNN": KNeighborsClassifier(),
"RF": RandomForestClassifier(n_estimators=100, random_state=42),
"GBM": GradientBoostingClassifier(n_estimators=100, random_state=42),
}
classifiers_balanced = {
"Logistic": LogisticRegression(class_weight="balanced", max_iter=1000, random_state=42),
"SVM": SVC(class_weight="balanced", random_state=42),
"RF": RandomForestClassifier(class_weight="balanced", n_estimators=100, random_state=42),
}
f1_scorer = make_scorer(f1_score, pos_label=1)
mcc_scorer = make_scorer(matthews_corrcoef)
results = []
# デフォルト
for name, clf in classifiers_default.items():
pipe = Pipeline([("scaler", StandardScaler()), ("clf", clf)])
f1 = cross_val_score(pipe, X, y, cv=cv, scoring=f1_scorer).mean()
mcc = cross_val_score(pipe, X, y, cv=cv, scoring=mcc_scorer).mean()
acc = cross_val_score(pipe, X, y, cv=cv, scoring="accuracy").mean()
results.append({"対策": "なし", "分類器": name, "F1": f1, "MCC": mcc, "Accuracy": acc})
# class_weight="balanced"
for name, clf in classifiers_balanced.items():
pipe = Pipeline([("scaler", StandardScaler()), ("clf", clf)])
f1 = cross_val_score(pipe, X, y, cv=cv, scoring=f1_scorer).mean()
mcc = cross_val_score(pipe, X, y, cv=cv, scoring=mcc_scorer).mean()
acc = cross_val_score(pipe, X, y, cv=cv, scoring="accuracy").mean()
results.append({"対策": "balanced", "分類器": name, "F1": f1, "MCC": mcc, "Accuracy": acc})
df = pd.DataFrame(results)
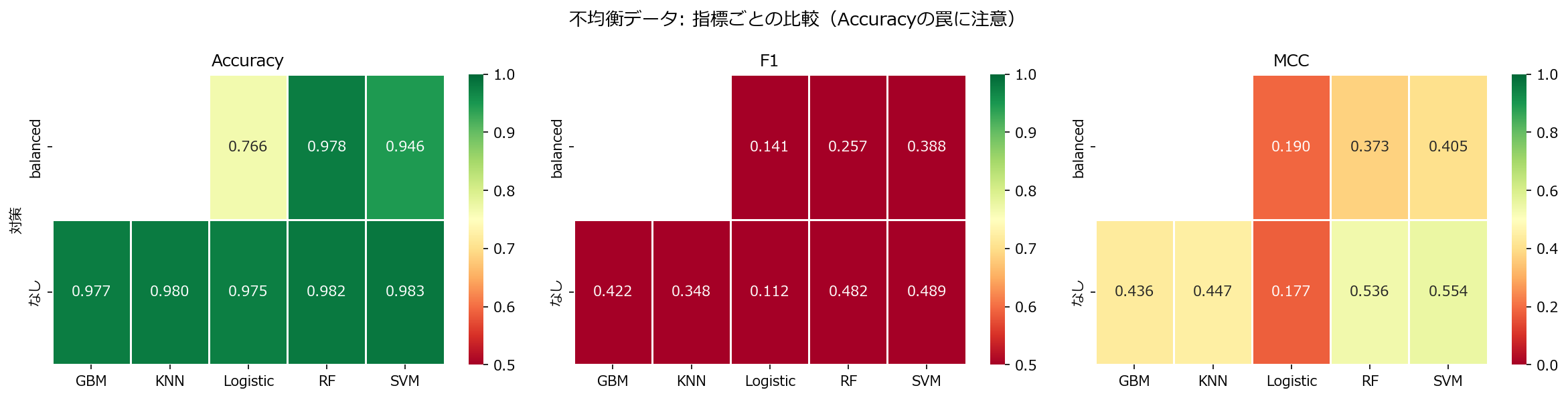
# ヒートマップ: F1 vs MCC vs Accuracy
fig, axes = plt.subplots(1, 3, figsize=(16, 4))
for i, metric in enumerate(["Accuracy", "F1", "MCC"]):
pivot = df.pivot_table(index="対策", columns="分類器", values=metric)
cmap = "RdYlGn" if metric != "Accuracy" else "RdYlGn"
sns.heatmap(pivot, annot=True, fmt=".3f", cmap=cmap,
linewidths=0.5, ax=axes[i],
vmin=0 if metric == "MCC" else 0.5,
vmax=1.0)
axes[i].set_title(f"{metric}")
axes[i].set_xlabel("")
if i > 0:
axes[i].set_ylabel("")
fig.suptitle("不均衡データ: 指標ごとの比較(Accuracyの罠に注意)", fontsize=13)
fig.tight_layout()
plt.show()
|