2.2.23
【ベンチマーク】混合型特徴量の分類
まとめ
- 連続値3つ + 順序尺度2つ + カテゴリ変数2つが混在する3クラスデータで、4つのエンコーディング × 6分類器を比較する。
- 木系モデルは順序エンコーディングだけで高精度を出し、線形モデルはOneHot + スケーリングが必須。
- TargetEncodingは木系モデルとの相性が良いが、リーク対策(CV内での計算)が欠かせない。
顧客データ・医療記録・アンケート結果など、実務データは連続値とカテゴリ変数が混在していることがほとんどだ。「とりあえずOneHotEncoding」で済ませがちだが、エンコーディングの選択がモデルの精度を大きく左右する。ここでは混合型特徴量を持つ合成データで最適な組み合わせを検証する。
1. データの特徴 #
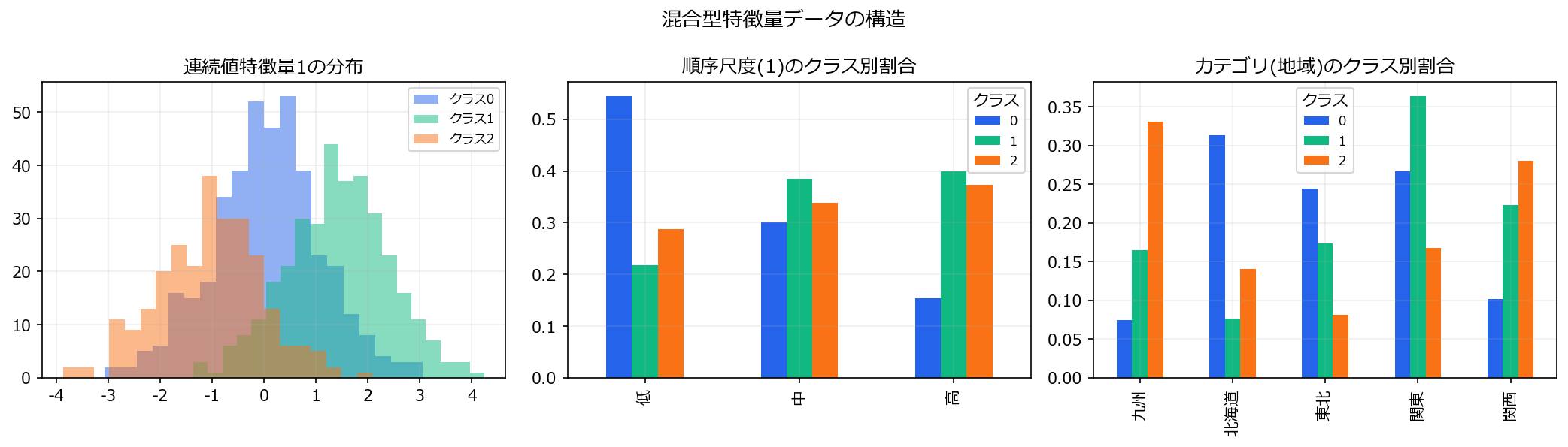
n=1000、3クラス分類- 連続値特徴量3つ(正規分布)
- 順序尺度特徴量2つ(低/中/高、S/M/L/XLなど順序あり)
- カテゴリ特徴量2つ(地域名や職種など順序なし、カーディナリティ=5〜8)
2. 合成データの生成 #
| |
3. 比較するパイプライン #
| エンコーディング | 説明 | 分類器 |
|---|---|---|
| OrdinalEncoding | すべての変数を整数に変換 | 6分類器 |
| OneHotEncoding | カテゴリ変数をダミー変数化 | 6分類器 |
| OneHot + StandardScaler | ダミー化後にスケーリング | 6分類器 |
| TargetEncoding | カテゴリをクラス平均で置換(CV内) | 6分類器 |
4. 実験と結果 #
| |
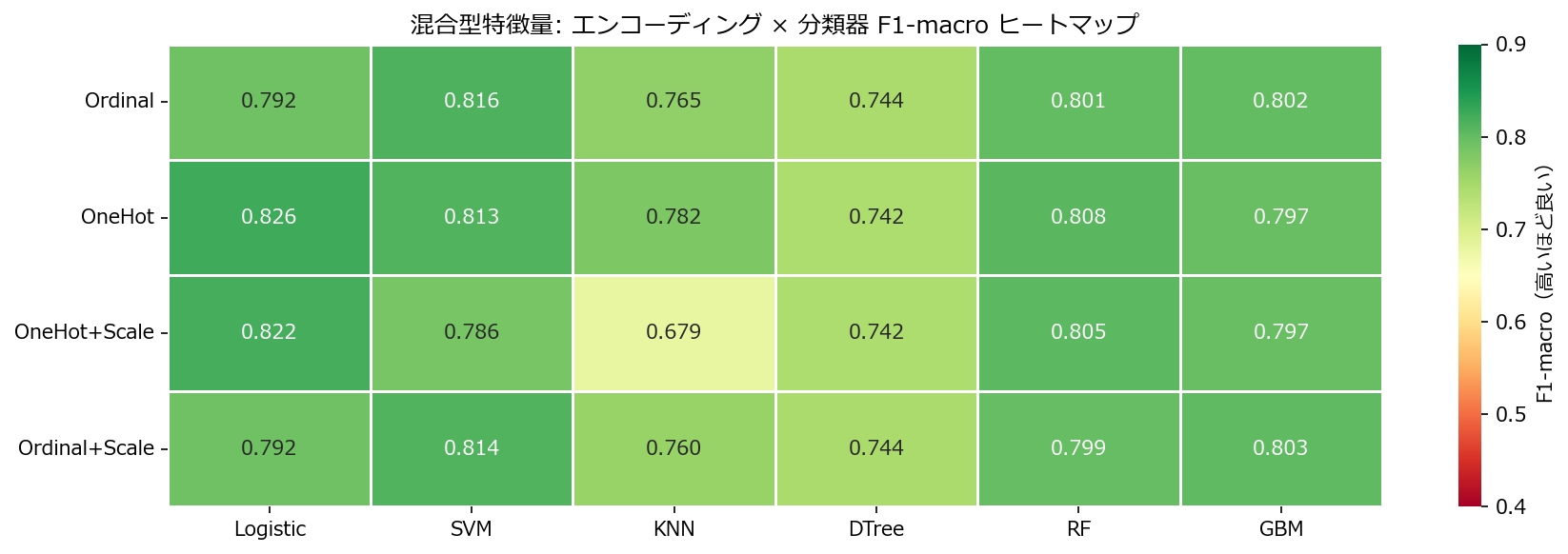
読み方のポイント #
- 木系モデル(DTree, RF, GBM)はOrdinalEncodingだけで十分な精度を出す。カテゴリの順序を「スプリット可能な数値」として扱えるため。
- 線形モデル(Logistic, SVM)はOneHot + StandardScalerが必須。Ordinalでは「地域=3 > 地域=1」という偽の順序を学習してしまう。
- KNNは距離ベースのため、スケーリングの有無で精度が大きく変わる。
5. 誤差パターン分析 #
| |
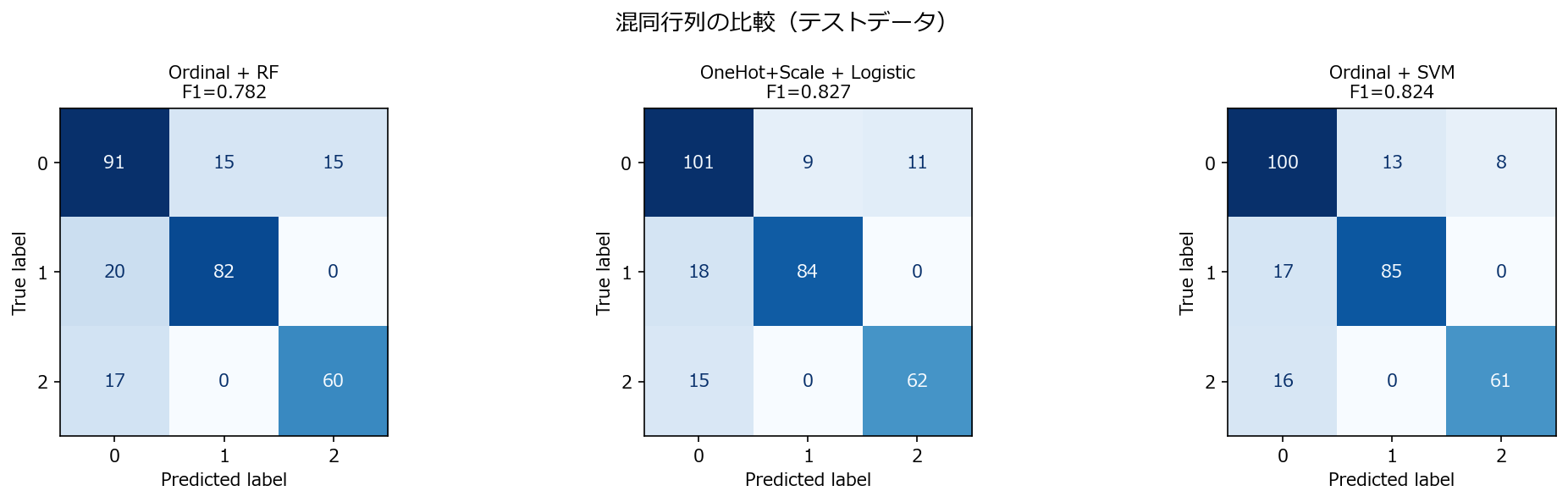
OrdinalでSVMを使うとカテゴリ変数の偽順序により特定クラス間の混同が増える。RFはOrdinalで問題なく動作し、Logisticは適切なエンコーディング + スケーリングで安定する。
6. よくある失敗パターン #
- カテゴリ変数にLabelEncoderを使って線形モデルに渡す: 偽の大小関係を学習してしまう。線形モデルにはOneHotを使う。
- 高カーディナリティ変数をOneHotする: カテゴリ数が100を超えると特徴量が爆発する。TargetEncodingや頻度エンコーディングを検討する。