1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
| from sklearn.preprocessing import StandardScaler
from sklearn.linear_model import LogisticRegression
from sklearn.svm import SVC
from sklearn.neighbors import KNeighborsClassifier
from sklearn.ensemble import RandomForestClassifier, GradientBoostingClassifier
from sklearn.metrics import accuracy_score
from sklearn.model_selection import cross_val_predict
import seaborn as sns
scaler = StandardScaler()
X_tr_s = scaler.fit_transform(X_train)
X_te_s = scaler.transform(X_test)
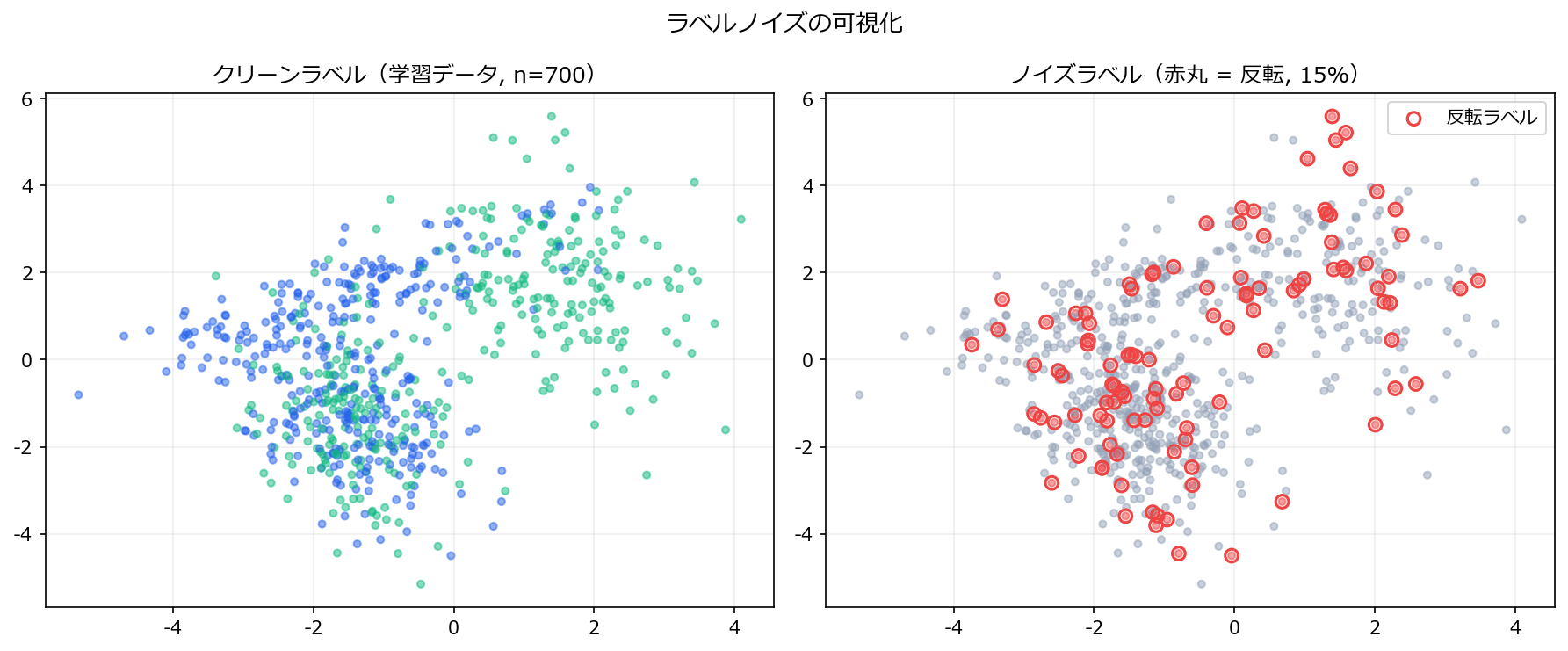
# --- ラベルクリーニング ---
# 交差検証で予測確率を取得し、確信度が低いサンプルを除去
lr_cv = LogisticRegression(max_iter=1000, random_state=42)
proba = cross_val_predict(lr_cv, X_tr_s, y_train_noisy, cv=5, method="predict_proba")
predicted_label = proba.argmax(axis=1)
confidence = proba.max(axis=1)
# 「予測と実ラベルが異なり、かつ確信度が高い」サンプルを除去
suspect = (predicted_label != y_train_noisy) & (confidence > 0.7)
clean_mask = ~suspect
X_tr_cleaned = X_tr_s[clean_mask]
y_tr_cleaned = y_train_noisy[clean_mask]
classifiers = {
"Logistic": LogisticRegression(max_iter=1000, random_state=42),
"SVM(linear)": SVC(kernel="linear", random_state=42),
"SVM(RBF)": SVC(kernel="rbf", random_state=42),
"KNN": KNeighborsClassifier(),
"RF": RandomForestClassifier(n_estimators=100, random_state=42),
"GBM": GradientBoostingClassifier(n_estimators=100, random_state=42),
}
results = []
for name, clf_template in classifiers.items():
for condition, X_fit, y_fit in [
("ノイズ", X_tr_s, y_train_noisy),
("クリーニング後", X_tr_cleaned, y_tr_cleaned),
("クリーン(参考)", X_tr_s, y_train_clean),
]:
from sklearn.base import clone
clf = clone(clf_template)
clf.fit(X_fit, y_fit)
acc = accuracy_score(y_test, clf.predict(X_te_s))
results.append({"条件": condition, "分類器": name, "Accuracy": acc})
df = pd.DataFrame(results)
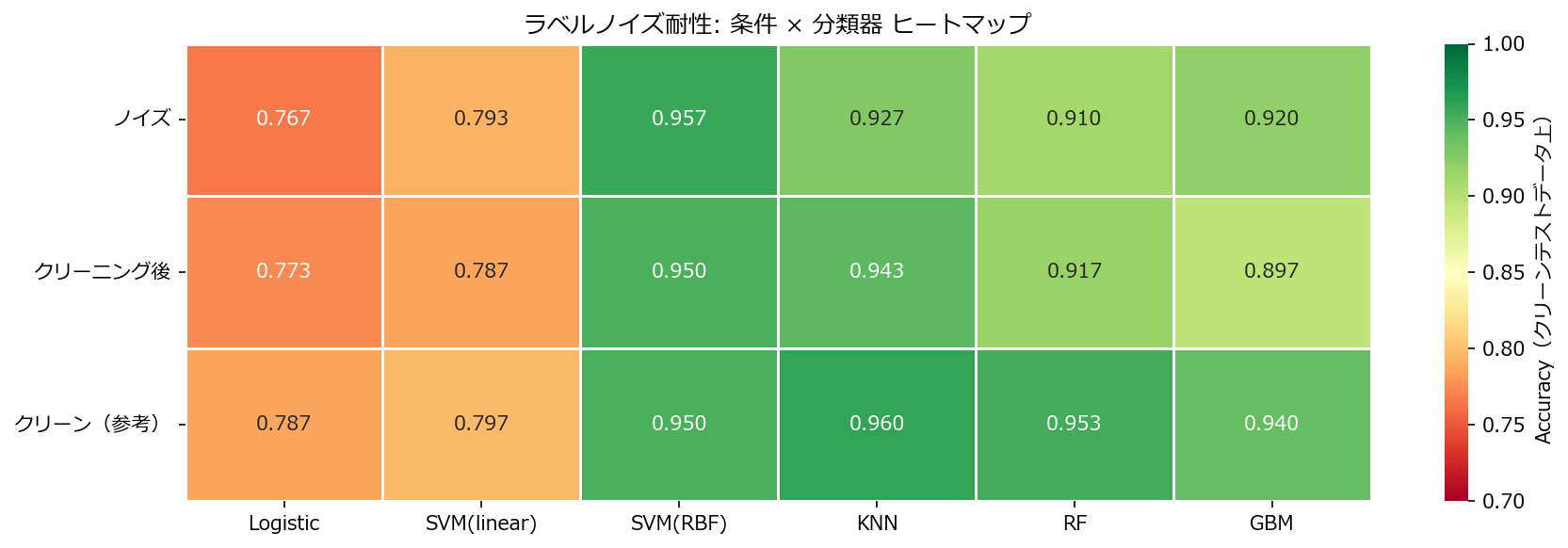
pivot = df.pivot_table(index="条件", columns="分類器", values="Accuracy")
cond_order = ["ノイズ", "クリーニング後", "クリーン(参考)"]
clf_order = ["Logistic", "SVM(linear)", "SVM(RBF)", "KNN", "RF", "GBM"]
pivot = pivot.reindex(index=[c for c in cond_order if c in pivot.index],
columns=[c for c in clf_order if c in pivot.columns])
fig, ax = plt.subplots(figsize=(12, 4))
sns.heatmap(pivot, annot=True, fmt=".3f", cmap="RdYlGn",
linewidths=0.5, ax=ax, vmin=0.7, vmax=1.0,
cbar_kws={"label": "Accuracy(クリーンテストデータ上)"})
ax.set_title("ラベルノイズ耐性: 条件 × 分類器 ヒートマップ")
ax.set_xlabel("")
ax.set_ylabel("")
fig.tight_layout()
plt.show()
|