2.2.4
線形判別分析 (LDA)
まとめ
- LDA はクラス間分散とクラス内分散の比を最大化する方向を求め、分類と次元削減の両方に利用できます。
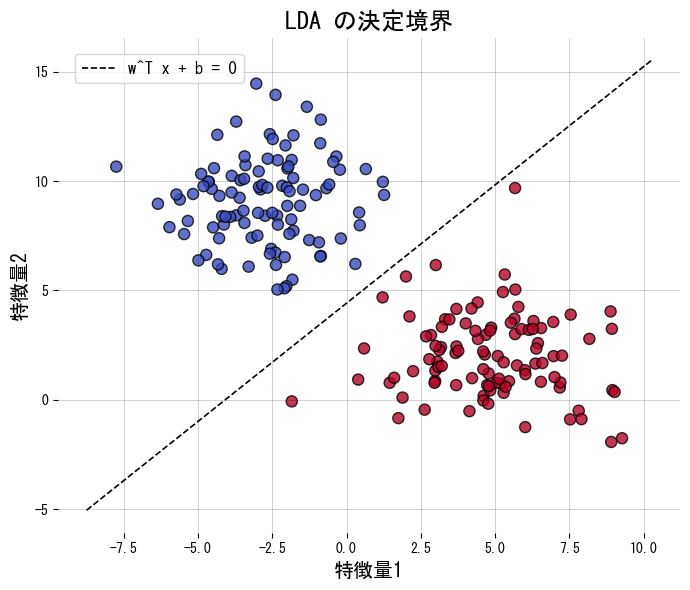
- 決定境界は \(\mathbf{w}^\top \mathbf{x} + b = 0\) の形になり、2次元なら直線、3次元なら平面として幾何的に解釈できます。
- 各クラスが同一共分散を持つガウス分布だと仮定すると、ベイズ最適に近い分類器を構築できます。
- scikit-learn の
LinearDiscriminantAnalysisを使えば、決定境界の描画や射影後の特徴量の確認が容易です。
- ロジスティック回帰 の概念を先に学ぶと理解がスムーズです
直感 #
LDA は「同じクラスのサンプルは近づけ、異なるクラスのサンプルは遠ざける」方向を探します。その方向に射影するとクラスが分離しやすくなり、直接分類に使ったり、低次元に圧縮して別の分類器に渡したりできます。
数式で見る #
2 クラスの場合、射影方向 \(\mathbf{w}\) は
$$ J(\mathbf{w}) = \frac{\mathbf{w}^\top \mathbf{S}_B \mathbf{w}}{\mathbf{w}^\top \mathbf{S}_W \mathbf{w}} $$を最大化することで求めます。ここで \(\mathbf{S}_B\) はクラス間散布行列、\(\mathbf{S}_W\) はクラス内散布行列です。多クラスでは最大でクラス数マイナス1個の射影方向が得られ、次元削減に利用できます。
Pythonによる実験 #
次のコードは2クラスの人工データに LDA を適用し、決定境界と射影後の1次元特徴量を描画します。transform を呼ぶと射影されたデータを直接取得できます。
| |
正則化と決定境界 #
正則化パラメータを変えると LDA の決定境界がどう変化するか確認できます。
参考文献 #
- Fisher, R. A. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7(2), 179 E88.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.
- 主成分分析(PCA) — 教師なし次元削減
- ロジスティック回帰 — 判別モデル
- LDA(次元削減) — 次元削減としてのLDA