2.2.3
パーセプトロン
まとめ
- パーセプトロンは線形に分離可能なデータで有限回の更新で収束する、古典的なオンライン学習アルゴリズムです。
- 重み付き和 \(\mathbf{w}^\top \mathbf{x} + b\) の符号だけで予測でき、誤分類したサンプルでのみ重みを更新します。
- 更新則が単純なため勾配法の直感をつかみやすく、学習率を調整しながら決定境界を少しずつ動かします。
- 非線形データにはそのままでは対応できないため、特徴量拡張やカーネルトリックと組み合わせます。
- ロジスティック回帰 の概念を先に学ぶと理解がスムーズです
直感 #
パーセプトロンは「誤分類したら境界をサンプルのある側へ少し動かす」という素朴な考え方で学習します。重みベクトル \(\mathbf{w}\) は決定境界の法線方向を表し、バイアス \(b\) がオフセットを表します。学習率 \(\eta\) を調整しながら境界を動かすと、誤りが減る方向へ徐々に収束します。
flowchart LR
A["入力x"] --> B["重み付き和\nw·x + b"]
B --> C["sign関数"]
C --> D["予測ŷ"]
D --> E{"誤分類?"}
E -->|Yes| F["重みを更新\nw ← w + ηyx"]
F --> B
E -->|No| G["次のサンプルへ"]
style A fill:#2563eb,color:#fff
style C fill:#1e40af,color:#fff
style G fill:#10b981,color:#fff
数式で見る #
予測は
$$ \hat{y} = \operatorname{sign}(\mathbf{w}^\top \mathbf{x} + b) $$で行います。サンプル \((\mathbf{x}_i, y_i)\) を誤分類した場合、以下のように更新します。
$$ \mathbf{w} \leftarrow \mathbf{w} + \eta\, y_i\, \mathbf{x}_i,\qquad b \leftarrow b + \eta\, y_i $$データが線形に分離可能であれば、この更新を繰り返すだけで有限回で収束することが知られています。
Pythonによる実験 #
次のコードは人工データにパーセプトロンを適用し、学習の進み具合と決定境界を可視化する例です。誤分類が 0 になった時点で更新を打ち切ります。
| |
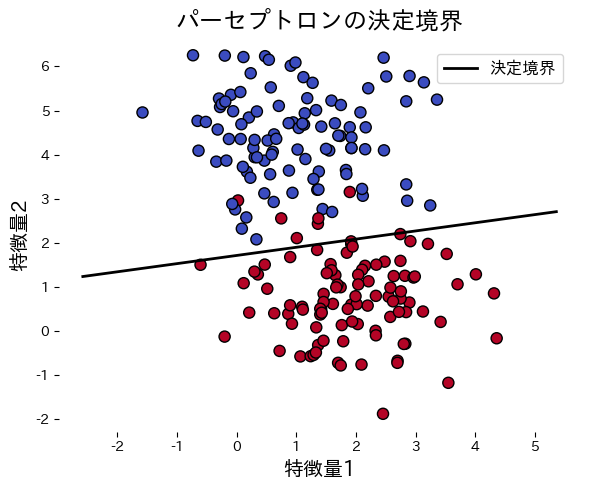
パーセプトロンはデータが線形分離可能でない場合、収束せずに振動し続けます。実データでは線形分離可能性を事前に確認できないため、max_iterでエポック数を制限してください。非線形データにはSVMやニューラルネットワークを検討してください。
scikit-learnのPerceptronクラスを使えばpenaltyでL1/L2正則化を追加でき、early_stopping=Trueで検証スコアが改善しなくなった時点で学習を打ち切れます。パーセプトロンはSGDClassifierのloss="perceptron"と等価です。
エポック数と決定境界 #
学習のエポック数を増やすと決定境界がどう変化するか確認できます。
まとめ #
- パーセプトロンは誤分類したサンプルでのみ重みを更新する、もっともシンプルな線形分類器です。
- データが線形分離可能であれば有限回の更新で収束することが保証されています。
- 更新則が単純なため、勾配法やオンライン学習の直感を掴むのに適した入門的手法です。
- 非線形データにはそのまま対応できないため、SVMやニューラルネットワークへの発展が必要です。
参考文献 #
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6), 386 E08.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.