2.5.4
DBSCAN
まとめ
- DBSCAN(Density-Based Spatial Clustering of Applications with Noise)は、密度が高い領域をクラスタ、疎な領域をノイズとして扱うアルゴリズムです。
- 距離の半径
epsと近傍に必要な点数min_samplesを指定し、点をコア・境界・ノイズの 3 種類に分類します。 - クラスタ数を事前に決める必要がなく、非凸な形のクラスタやノイズを含むデータに強いのが特徴です。
min_samples-距離プロットを手掛かりにepsを調整し、距離のスケールを揃えるために標準化しておくと安定します。
直感 #
DBSCAN は「点の周囲に十分な仲間がいるかどうか」を基準にクラスタを構成します。
- コアポイント: 半径
epsの円内にmin_samples個以上の点がある点。 - 境界ポイント: コアポイントの近傍に存在するが、自分自身は条件を満たさない点。
- ノイズ: コアにも境界にも分類されない孤立した点。
コアポイント同士が鎖のようにつながると同じ密度領域として扱われ、その領域が 1 つのクラスタになります。クラスタの形が不規則でも対応できますが、密度差が大きいデータではパラメータ調整が重要です。
flowchart LR
A["各点のε近傍\nを計算"] --> B{"min_samples\n以上?"}
B -->|Yes| C["コアポイント"]
B -->|No| D{"コアの\n近傍?"}
D -->|Yes| E["境界ポイント"]
D -->|No| F["ノイズ"]
C --> G["密度連結な\nコアを統合"]
G --> H["クラスタ形成"]
style A fill:#2563eb,color:#fff
style C fill:#1e40af,color:#fff
style H fill:#10b981,color:#fff
style F fill:#ef4444,color:#fff
数式で見る #
データ集合 \(\mathcal{X}\) の点 \(x_i\) に対し、eps で定義される \(\varepsilon\)-近傍は
です。近傍に十分な点が存在すればコアポイントになります。
$$ |\mathcal{N}_\varepsilon(x_i)| \ge \texttt{min\_samples} $$コアポイント同士が密度連結であれば同じクラスタに属し、境界ポイントはクラスタにぶら下がる形で所属します。ノイズはどのクラスタにも属さない点です。
Pythonで確かめる #
標準化した月型データに DBSCAN を適用し、クラスタ数とノイズ点の数を確認します。
| |
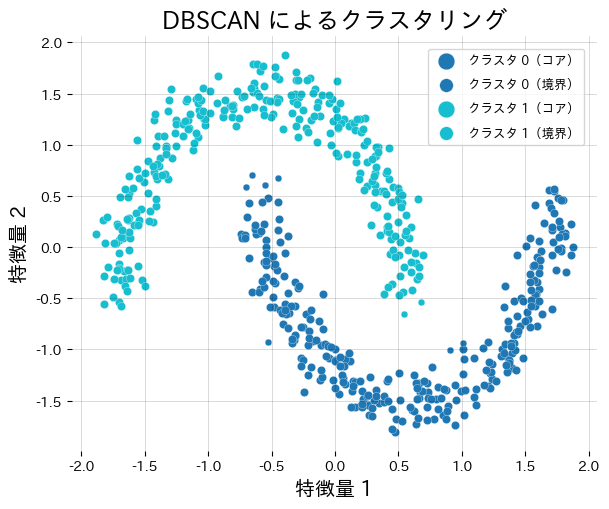
DBSCANはクラスター間の密度が大きく異なるデータには苦手です。epsを小さくすると疎なクラスターがノイズに分解され、大きくすると密なクラスターが結合してしまいます。密度差が大きい場合はHDBSCANを検討してください。
epsの選び方に迷ったら、各点のmin_samples番目に近い点までの距離をソートしてプロットし、急激に増加する「肘」の位置をepsの候補にしてください。NearestNeighborsのkneighborsメソッドで簡単に計算できます。
eps とクラスタリング結果 #
eps を変えるとクラスタの数とノイズ点がどう変わるか確認できます。
まとめ #
- DBSCANは密度が高い領域をクラスター、疎な領域をノイズとして自動的に分離します。
- クラスター数を事前に指定する必要がなく、非凸な形のクラスターも扱えます。
epsとmin_samplesの2つのパラメーターがクラスタリングの品質を決定します。- 特徴量の標準化は必須で、スケールが揃っていないと距離計算が偏りクラスター構造を正しく捉えられません。
参考文献 #
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. (1996). A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. KDD.
- Schubert, E., Sander, J., Ester, M., Kriegel, H.-P., & Xu, X. (2017). DBSCAN Revisited, Revisited. ACM Transactions on Database Systems.
- scikit-learn developers. (2024). Clustering. https://scikit-learn.org/stable/modules/clustering.html
- HDBSCAN — DBSCAN の階層的拡張
- k-means — セントロイドベースの代替手法
- スペクトラルクラスタリング — グラフベースの手法
- UMAP — クラスタリング前の次元削減に有効