2.5.5
ガウス混合モデル (GMM)
まとめ
- ガウス混合モデルは複数の多変量正規分布を重ね合わせ、データ全体の確率分布を表す生成モデルです。
- 各サンプルに対してクラスタ所属確率(責務)が推定でき、ハードな割り当てでは見えない曖昧さを表現できます。
- パラメータは EM アルゴリズムで推定し、分散共分散行列の形を
full,tied,diag,sphericalから選択できます。 - BIC や AIC を使ったモデル選択、複数回の初期化による安定化が実務では不可欠です。
- k-meansクラスタリング の概念を先に学ぶと理解がスムーズです
直感 #
「データは複数のガウス分布が混ざったもの」と仮定すると、各クラスタは平均ベクトルと共分散行列を持つ楕円体として表現できます。k-means が最も近いクラスタを 1 つだけ返すのに対し、GMM は「クラスタ \(k\) がサンプル \(x_i\) を生み出した確率 \(\gamma_{ik}\)」を返すソフトクラスタリングを行います。
flowchart LR
A["データ"] --> B["パラメータ\n初期化"]
B --> C["E-step\n責務を計算"]
C --> D["M-step\nμ,Σ,πを更新"]
D --> E{"収束?"}
E -->|No| C
E -->|Yes| F["ソフト\nクラスタリング"]
style A fill:#2563eb,color:#fff
style C fill:#1e40af,color:#fff
style F fill:#10b981,color:#fff
数式 #
入力ベクトル \(\mathbf{x}\) の確率密度は
$$ p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \, \mathcal{N}(\mathbf{x} \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k), $$で表されます。\(\pi_k\) は混合係数(非負で総和が 1)、\(\boldsymbol{\mu}_k\) は平均、\(\boldsymbol{\Sigma}_k\) は共分散行列です。EM アルゴリズムでは以下を収束まで繰り返します。
- E-step: 責務 \(\gamma_{ik}\) を求める。 $$ \gamma_{ik} = \frac{\pi_k \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)} {\sum_{j=1}^K \pi_j \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)}. $$
- M-step: 責務を重みとして \(\pi_k, \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k\) を更新。
対数尤度は単調に増加し、局所最大に収束します。
Pythonで確かめる #
合成データに GMM を適用し、クラスタ中心と責務を可視化します。
| |
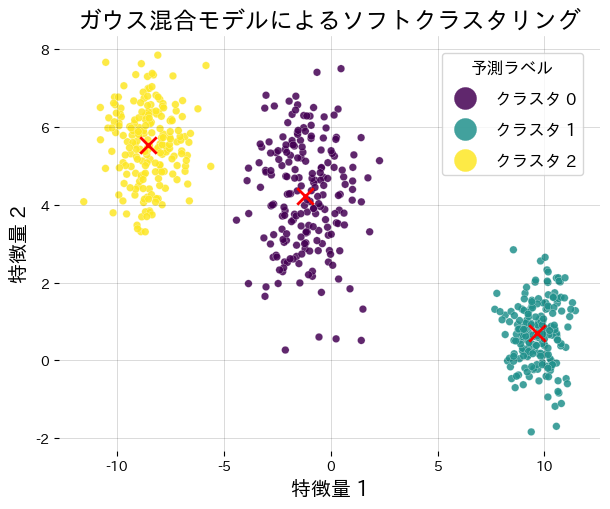
EMアルゴリズムは局所最適解に収束するため、初期値によって結果が変わります。n_initを10以上に設定して複数回実行し、もっとも対数尤度が高い結果を採用してください。また、共分散行列の形をfullにすると高次元データではパラメーター数が急増し、過学習しやすくなります。
コンポーネント数の選択にはBICを使うのが実践的です。GaussianMixtureのbicメソッドで複数のn_componentsを比較し、BICが最小になる値を選んでください。クラスターの形が球状に近い場合はcovariance_type="diag"にするとパラメーター数を抑えられます。
成分数と混合ガウス分布 #
成分数を変えるとクラスタ割り当てと BIC/AIC がどう変化するか確認できます。
まとめ #
- ガウス混合モデルは複数のガウス分布を重ね合わせてデータの確率分布を表現する生成モデルです。
- 各サンプルに対してクラスター所属確率(責務)を返すソフトクラスタリングが可能です。
- パラメーターはEMアルゴリズムで推定し、局所最適解を避けるために複数回の初期化が重要です。
- BICやAICを使ったモデル選択により、適切なコンポーネント数を決定できます。
参考文献 #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, Series B.
- scikit-learn developers. (2024). Gaussian Mixture Models. https://scikit-learn.org/stable/modules/mixture.html