2.5.1
k-means
- k-meansは「距離が近い点同士をまとめる」という直感をもとに、セントロイド(重心)を反復更新してデータを \(k\) 個に分割する。
- 目的関数は各サンプルと所属クラスターのセントロイドとの距離二乗和(WCSS)で、これを最小にする配置を探す。
- クラスター数 \(k\) の選択にはエルボー法やシルエット係数を使い、データ構造とビジネス要件を踏まえて判断する。
直感 #
k-meansは教師なし学習のもっとも基本的なクラスターリング手法です。\(k\) 個のセントロイドをランダムに配置し、「各点をもっとも近いセントロイドに割り当てる」→「セントロイドをクラスターの平均に移動する」を収束するまで繰り返す。アルゴリズムは単純だが、初期値や \(k\) の選び方で結果が変わるため、適切な評価指標と組み合わせて使う必要がある。
アルゴリズムの詳細 #
目的関数 #
k-meansはWCSS(Within-Cluster Sum of Squares)、すなわち各サンプルと所属クラスターのセントロイドとの距離二乗和を最小化します。
$$ J = \sum_{k=1}^{K} \sum_{\mathbf{x}_i \in C_k} \lVert \mathbf{x}_i - \boldsymbol{\mu}_k \rVert^2 $$ここで\(C_k\)はクラスター\(k\)に属するサンプルの集合、\(\boldsymbol{\mu}_k\)はクラスター\(k\)のセントロイドです。この目的関数はNP困難ですが、以下の2ステップを交互に繰り返すことで局所最適解に収束します。
Lloyd のアルゴリズム #
割り当てステップ: 各サンプル\(\mathbf{x}_i\)をもっとも近いセントロイドのクラスターに割り当てます。
$$ c_i = \arg\min_{k} \lVert \mathbf{x}_i - \boldsymbol{\mu}_k \rVert^2 $$更新ステップ: 各クラスターのセントロイドを、そのクラスターに属するサンプルの平均に更新します。
$$ \boldsymbol{\mu}_k = \frac{1}{|C_k|} \sum_{\mathbf{x}_i \in C_k} \mathbf{x}_i $$割り当てが変化しなくなるまで1–2を繰り返します。
収束の保証 #
各ステップで目的関数\(J\)は単調に減少します。
- 割り当てステップでは、各サンプルをもっとも近いセントロイドに再割り当てするため、\(J\)は減少または不変です
- 更新ステップでは、クラスター内の平均がユークリッド距離の二乗和を最小にする点であるため、\(J\)は減少または不変です
\(J\)は下に有界(\(J \ge 0\))かつ単調非増加であるため、有限回のステップで収束が保証されます。ただし、収束先は大域的最適解とは限りません。
k-means++ 初期化 #
ランダム初期化では悪い局所解に陥りやすいため、k-means++では初期セントロイドを以下の手順で選びます。
- 最初のセントロイド\(\boldsymbol{\mu}_1\)をデータからランダムに選びます
- 各サンプル\(\mathbf{x}_i\)について、もっとも近い既存セントロイドとの距離\(D(\mathbf{x}_i)\)を計算します
- \(D(\mathbf{x}_i)^2\)に比例する確率で次のセントロイドを選びます
- \(K\)個のセントロイドが選ばれるまで2–3を繰り返します
この初期化により、期待値で\(O(\log K)\)倍以内の近似が保証されます。
$$ \mathbb{E}[J_{\text{k-means++}}] \le 8(\ln K + 2) \cdot J_{\text{opt}} $$参考リンク
Lloyd, S. (1982). Least squares quantization in PCM. IEEE Transactions on Information Theory, 28(2), 129–137.
Arthur, D., & Vassilvitskii, S. (2007). k-means++: The Advantages of Careful Seeding. Proceedings of the 18th Annual ACM-SIAM Symposium on Discrete Algorithms (SODA), 1027–1035.
詳細な解説 #
ライブラリと実験データ #
| |
3つの塊を持つ合成データを生成します。
| |
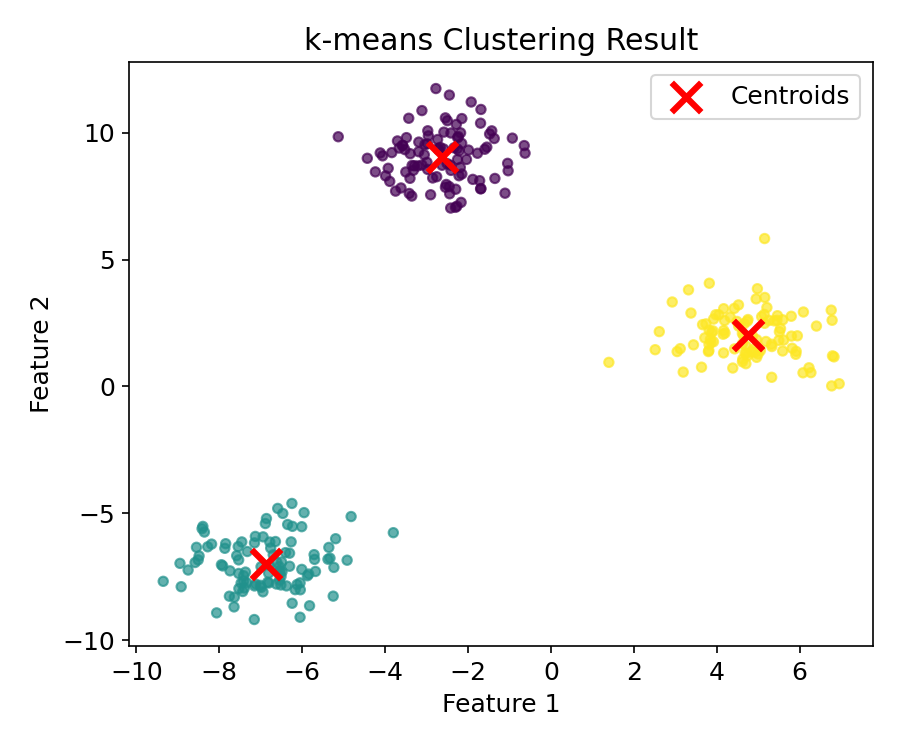
基本的な学習 #
| |
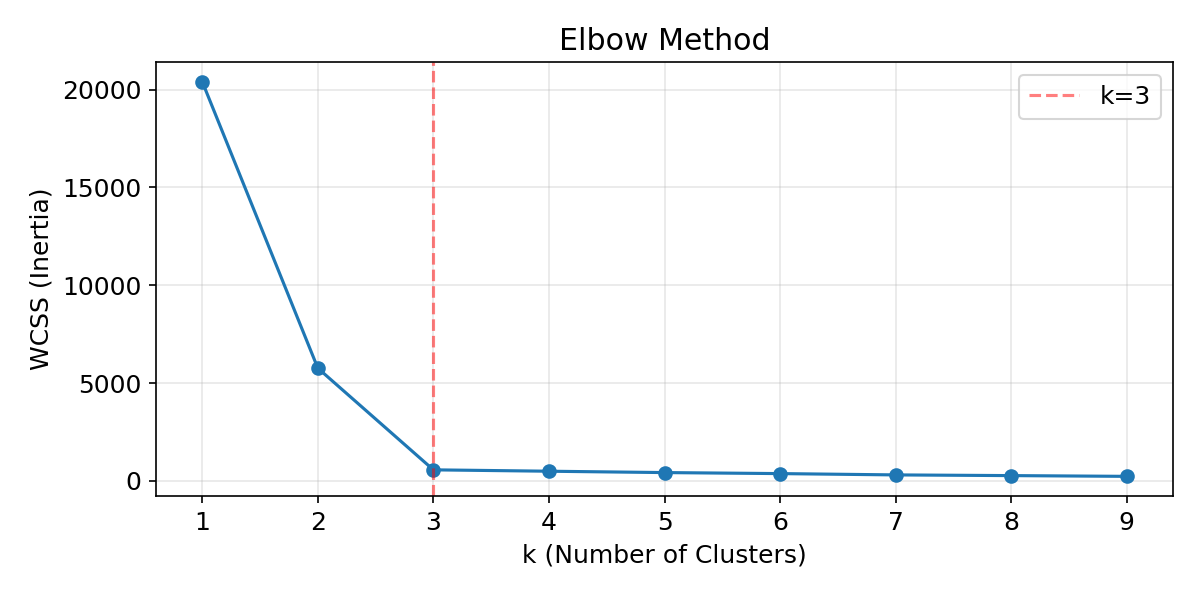
エルボー法でクラスター数を選ぶ #
WCSS(Within-Cluster Sum of Squares)を \(k\) ごとに計算し、減少が鈍化する「肘」の位置を \(k\) の候補とします。
| |
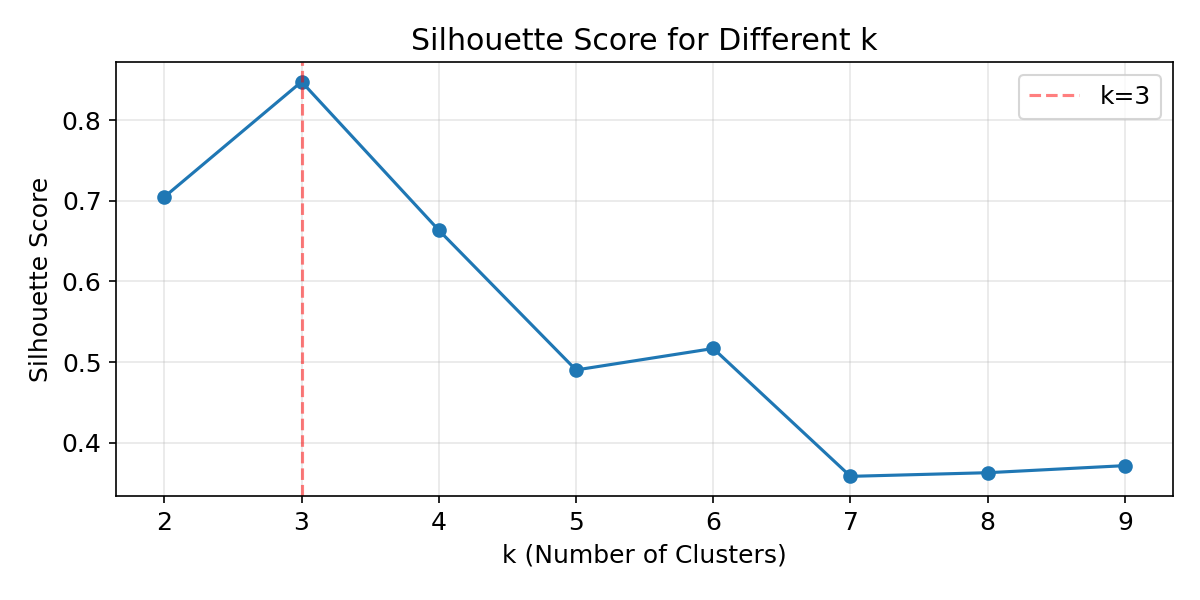
シルエット係数でクラスター数を評価 #
シルエット係数はクラスターの凝集度と分離度のバランスを測ります。1に近いほどクラスターが明確に分かれていることを示します。
| |
n_initの役割 #
k-meansはランダムな初期値に依存するため、n_init回の試行から最良の結果を採用します。
| |
k-meansはクラスターが球状で等分散であることを仮定しています。三日月型や密度が大きく異なるクラスターには適用できません。また、特徴量のスケールが異なる場合はStandardScalerで標準化してから適用してください。
エルボー法だけでは「肘」の位置が曖昧なことがあります。シルエット係数と併用し、複数の指標で \(k\) を判断するのが実務的です。n_init=10以上に設定して初期値依存を減らすことも忘れずに行ってください。
まとめ #
- k-meansはセントロイドの割り当てと更新を繰り返すことで、データを \(k\) 個のクラスターに分割します。
- エルボー法やシルエット係数を使って、適切なクラスター数 \(k\) を定量的に選択できます。
- 初期値に依存するため、
n_initパラメーターで複数回の試行から最良の結果を採用します。 - 球状クラスターを仮定するため、非凸な形状のクラスターにはDBSCANなど密度ベースの手法が適しています。