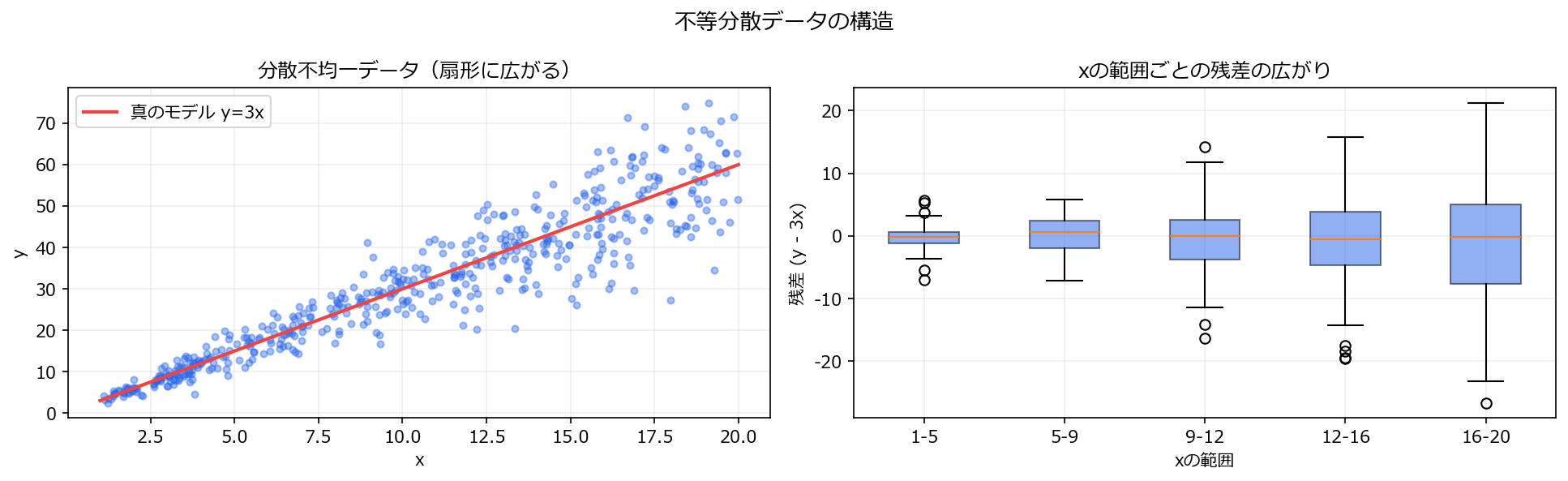
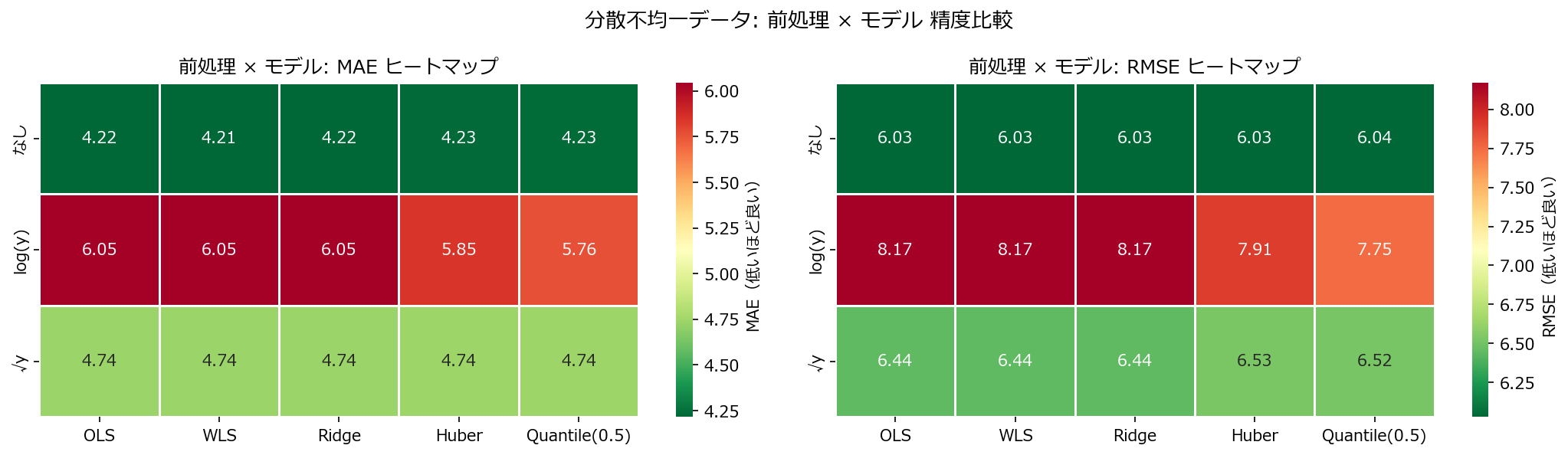
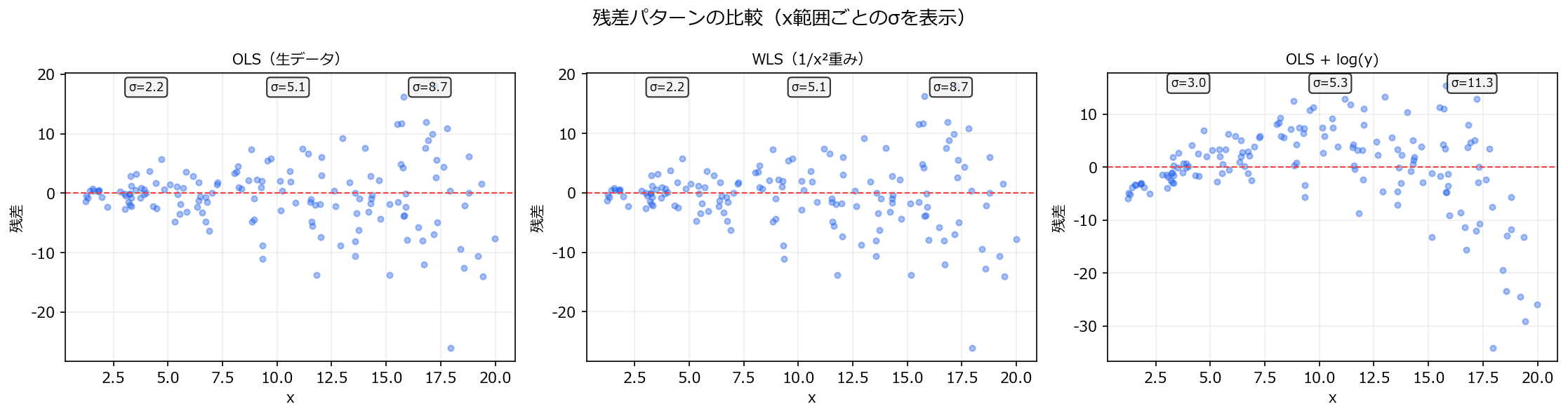
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
81
82
83
84
85
86
87
88
89
90
91
92
93
94
95
96
97
98
99
| from sklearn.model_selection import cross_val_score, KFold
from sklearn.linear_model import LinearRegression, Ridge, HuberRegressor, QuantileRegressor
from sklearn.preprocessing import FunctionTransformer
from sklearn.pipeline import Pipeline
from sklearn.base import clone
import seaborn as sns
cv = KFold(n_splits=5, shuffle=True, random_state=42)
X = x.reshape(-1, 1)
# 変換関数
def log_transform(y):
return np.log1p(y)
def sqrt_transform(y):
return np.sqrt(np.maximum(y, 0))
def inv_log(y):
return np.expm1(y)
def inv_sqrt(y):
return y ** 2
models = {
"OLS": LinearRegression(),
"WLS": LinearRegression(), # 手動で重み適用
"Ridge": Ridge(alpha=1.0),
"Huber": HuberRegressor(epsilon=1.35),
"Quantile(0.5)": QuantileRegressor(quantile=0.5, alpha=0.0, solver="highs"),
}
transforms = {
"なし": (None, None),
"log(y)": (log_transform, inv_log),
"√y": (sqrt_transform, inv_sqrt),
}
results = []
for trans_name, (fwd, inv) in transforms.items():
for mdl_name, mdl in models.items():
maes, rmses = [], []
for train_idx, test_idx in cv.split(X):
X_tr, X_te = X[train_idx], X[test_idx]
y_tr, y_te = y[train_idx], y[test_idx]
y_fit = fwd(y_tr) if fwd else y_tr
m = clone(mdl)
if mdl_name == "WLS" and fwd is None:
# 重みを 1/x² に設定
w = 1.0 / (X_tr.ravel() ** 2 + 1e-6)
m.fit(X_tr, y_fit, sample_weight=w)
else:
try:
m.fit(X_tr, y_fit)
except Exception:
maes.append(np.nan)
rmses.append(np.nan)
continue
pred = m.predict(X_te)
if inv:
pred = inv(pred)
maes.append(np.mean(np.abs(y_te - pred)))
rmses.append(np.sqrt(np.mean((y_te - pred) ** 2)))
results.append({
"前処理": trans_name, "モデル": mdl_name,
"MAE": np.nanmean(maes), "RMSE": np.nanmean(rmses),
})
df_res = pd.DataFrame(results)
pivot = df_res.pivot_table(index="前処理", columns="モデル", values="MAE")
trans_order = ["なし", "log(y)", "√y"]
mdl_order = ["OLS", "WLS", "Ridge", "Huber", "Quantile(0.5)"]
pivot = pivot.reindex(index=[t for t in trans_order if t in pivot.index],
columns=[m for m in mdl_order if m in pivot.columns])
fig, axes = plt.subplots(1, 2, figsize=(14, 4))
sns.heatmap(pivot, annot=True, fmt=".2f", cmap="RdYlGn_r",
linewidths=0.5, ax=axes[0], cbar_kws={"label": "MAE(低いほど良い)"})
axes[0].set_title("前処理 × モデル: MAE ヒートマップ")
axes[0].set_xlabel("")
axes[0].set_ylabel("")
pivot_rmse = df_res.pivot_table(index="前処理", columns="モデル", values="RMSE")
pivot_rmse = pivot_rmse.reindex(index=[t for t in trans_order if t in pivot_rmse.index],
columns=[m for m in mdl_order if m in pivot_rmse.columns])
sns.heatmap(pivot_rmse, annot=True, fmt=".2f", cmap="RdYlGn_r",
linewidths=0.5, ax=axes[1], cbar_kws={"label": "RMSE(低いほど良い)"})
axes[1].set_title("前処理 × モデル: RMSE ヒートマップ")
axes[1].set_xlabel("")
axes[1].set_ylabel("")
fig.suptitle("分散不均一データ: 前処理 × モデル 精度比較", fontsize=13)
fig.tight_layout()
plt.show()
|