2.1.1
線形回帰
まとめ
- 線形回帰は入力と出力の線形関係をモデル化する最も基本的な回帰モデルであり、予測と解釈の両方に使える。
- 最小二乗法は残差二乗和を最小化することで係数を推定し、解析的な解が得られるため仕組みが理解しやすい。
- 傾き係数は「入力が 1 増えたとき出力がどれだけ変化するか」、切片は入力が 0 のときの期待値として解釈できる。
- ノイズや外れ値が大きい場合には標準化やロバスト手法も検討し、前処理と評価指標を組み合わせて活用する。
直感 #
観測されたデータ \((x_i, y_i)\) が散布図上でほぼ直線状に並ぶとき、未知の入力に対しても直線を延長すればよいのではないか、という素朴な発想から生まれたのが線形回帰です。最小二乗法はプロットした点の近くに一本の直線を引き、その直線からのズレが全体として最も小さくなるように傾きと切片を選びます。
flowchart LR
A["観測データ\n(x, y)"] --> B["線形モデル\ny = wx + b"]
B --> C["残差を計算\nε = y − ŷ"]
C --> D["SSEを最小化\nΣε² → min"]
D --> E["解析解\nw, b を確定"]
E --> F["予測値 ŷ"]
style A fill:#2563eb,color:#fff
style D fill:#1e40af,color:#fff
style F fill:#10b981,color:#fff
具体的な数式 #
一次の線形モデルは
$$ y = w x + b $$で表されます。観測値と予測値の差(残差)\(\epsilon_i = y_i - (w x_i + b)\) の二乗和を目的関数
$$ L(w, b) = \sum_{i=1}^{n} \big(y_i - (w x_i + b)\big)^2 $$として最小化すると、解析的に次の解が得られます。
$$ w = \frac{\sum_{i=1}^{n} (x_i - \bar{x})(y_i - \bar{y})}{\sum_{i=1}^{n} (x_i - \bar{x})^2}, \qquad b = \bar{y} - w \bar{x} $$ここで \(\bar{x}, \bar{y}\) はそれぞれの平均です。複数の入力を使う重回帰でも、ベクトルと行列を用いて同様に最小二乗解を導くことができます。
多重共線性(重回帰で説明変数どうしが強く相関している状態)があると、係数 \(w\) が不安定になり解釈が困難になります。VIF(分散インフレ係数)が10を超える変数は除外や結合を検討してください。
Pythonを用いた実験や説明 #
次のコードは scikit-learn を使って単回帰モデルを学習し、推定された直線と観測値を描画します。コード本体は既存のものをそのまま利用しています。
| |
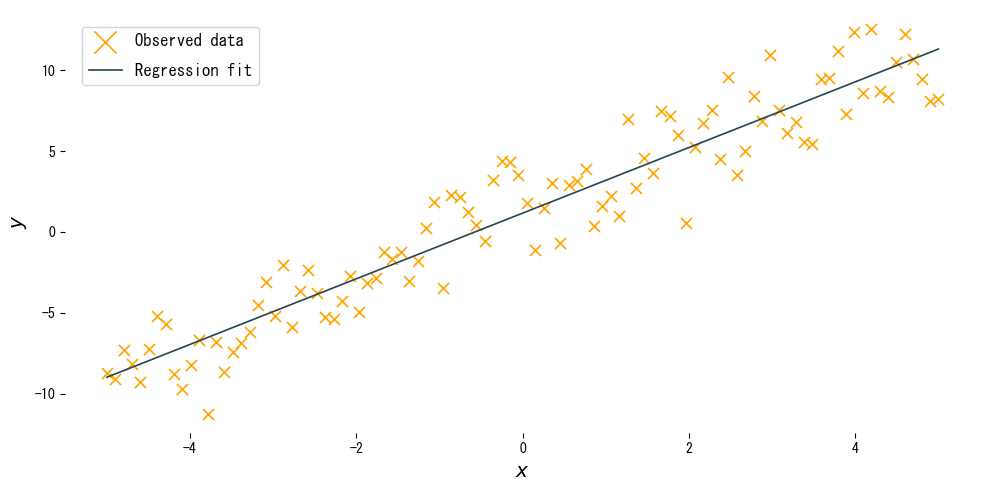
実行結果の読み方 #
- 傾き \(w\): 入力が 1 増えたときに出力がどれだけ増減するかを表し、真の傾きに近い値が推定されます。
- 切片 \(b\): 入力が 0 のときの平均的な出力であり、直線の位置を上下に調整します。
StandardScalerで特徴量を標準化すると、スケールの異なる入力でも安定して学習できます。
特徴量のスケール差が大きい場合は StandardScaler を適用すると、係数の大小を直接比較できるようになります。make_pipeline に組み込むと学習・推論で一貫したスケーリングが保たれます。
ノイズと回帰直線 #
ノイズの大きさが回帰直線のフィッティングにどう影響するか確認できます。
まとめ #
- 線形回帰は入力と出力の線形関係を最小二乗法で推定する、もっとも基本的な回帰モデルです。
- 残差二乗和(SSE)を最小化することで解析的な解が得られ、係数の意味を直接解釈できます。
- 傾き \(w\) は「入力が1増えたときの出力変化量」、切片 \(b\) は「入力がゼロのときの期待値」として読みます。
- 多重共線性・外れ値・スケール差が精度に影響するため、前処理と診断指標を組み合わせて活用します。
参考文献 #
- Draper, N. R., & Smith, H. (1998). Applied Regression Analysis (3rd ed.). John Wiley & Sons.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.
- リッジ・ラッソ回帰 — 正則化つき線形回帰
- 多項式回帰 — 非線形への拡張
- ベイズ線形回帰 — 確率的な線形回帰
- Huber Loss — 外れ値に頑健な損失関数