2.1.11
加重最小二乗法 (WLS)
まとめ
- 加重最小二乗法 (WLS) は観測ごとの信頼度に応じて重みを割り当て、異質なノイズを持つデータでも妥当な回帰直線を推定する。
- 重みを二乗誤差に掛けることで、分散の小さい観測ほど強く反映され、ノイズの大きい点に引きずられにくくなる。
- 標準の
LinearRegressionにsample_weightを指定すれば WLS を実行できる。 - 重みは既知の分散、残差の推定、ドメイン知識など複数の観点を組み合わせて設計する。
直感 #
通常の最小二乗法はすべての観測が同じ信頼度を持つと仮定します。しかし実務では、センサー性能や測定回数によって精度が大きく異なることがよくあります。WLS は「信頼できる点の意見をより尊重する」ように重みを付け直し、線形回帰の枠組みで異質なデータを扱います。
具体的な数式 #
観測ごとに重み \(w_i > 0\) を与えて目的関数
$$ L(\boldsymbol\beta, b) = \sum_{i=1}^{n} w_i \left(y_i - (\boldsymbol\beta^\top \mathbf{x}_i + b)\right)^2 $$を最小化します。理想的には \(w_i \propto 1/\sigma_i^2\)(分散の逆数)と設定し、信頼度の高いデータ点ほど重みを大きくします。
Pythonを用いた実験や説明 #
ノイズレベルが区間で異なるデータに WLS を適用する例です。
| |
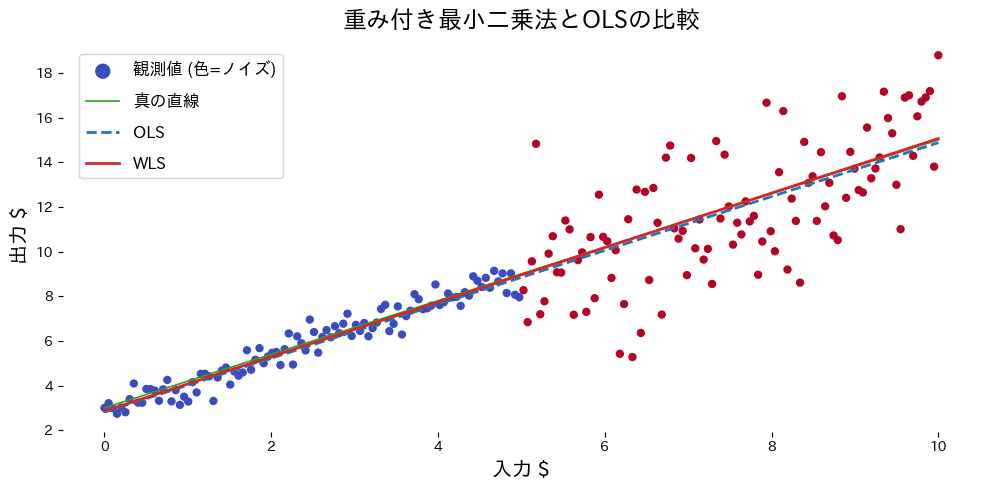
実行結果の読み方 #
weightsを与えることでノイズの小さい区間がより重視され、真の直線に近い推定になる。- OLS の直線はノイズの大きい区間に引っ張られ、傾きが過小評価されやすい。
- 重みを適切に設定することが性能改善の鍵となる。
よくある質問 #
OLSとWLSはどう使い分ける? #
OLS(通常最小二乗法)は全観測が等分散であることを前提とします。残差プロットで分散が入力値に依存して変化する(不均一分散、ヘテロスケダスティシティ)ことが確認された場合にWLSを使います。Breusch-PaganテストやWhiteテストで不均一分散を統計的に検定してから判断するのが標準的です。
重みの決め方は? #
主な設定方法:
- 分散の逆数:各観測の誤差分散が既知または推定できる場合は \(w_i = 1/\hat{\sigma}_i^2\)
- 測定回数の平方根:複数回測定の平均値を使う場合は測定回数 \(n_i\) を重みに
- 残差の逆数:2段階推定(まずOLS残差を計算し、残差の絶対値の逆数を重みに)
- ドメイン知識:センサー精度や信頼度スコアなど外部情報から設計
WLSとGLSの違いは? #
WLS(加重最小二乗法)は誤差の分散のみが観測ごとに異なる場合(対角共分散行列)を扱います。GLS(一般化最小二乗法)は誤差間に相関がある場合も含む一般的な枠組みで、WLSはGLSの特殊ケースです。時系列の自己相関がある場合はFeasible GLS(FGLS)が必要です。
sklearnでWLSを実行するには? #
LinearRegression.fit(X, y, sample_weight=weights)のsample_weight引数に重みベクトルを渡すだけです。重みは正の値で、分散の逆数(1 / sigma**2)として設定するのが理想的です。
参考文献 #
- Carroll, R. J., & Ruppert, D. (1988). Transformation and Weighting in Regression. Chapman & Hall.
- Seber, G. A. F., & Lee, A. J. (2012). Linear Regression Analysis (2nd ed.). Wiley.