2.2.4
Γραμμική Διακριτική Ανάλυση (LDA)
Σύνοψη
- Η LDA βρίσκει κατευθύνσεις που μεγιστοποιούν τον λόγο της μεταξύ-κλάσεων διακύμανσης προς την εντός-κλάσεων διακύμανση, εξυπηρετώντας τόσο την ταξινόμηση όσο και τη μείωση διαστάσεων.
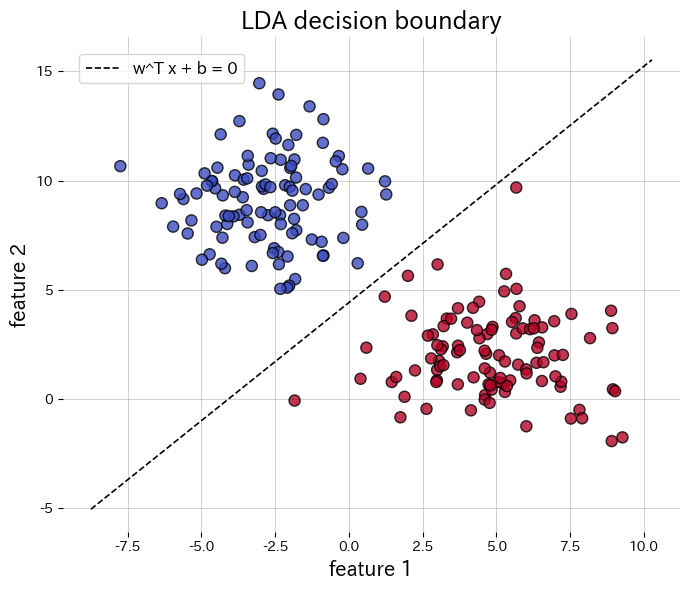
- Το όριο απόφασης έχει τη μορφή \(\mathbf{w}^\top \mathbf{x} + b = 0\), που γίνεται γραμμή σε 2D ή επίπεδο σε 3D, δίνοντας σαφή γεωμετρική ερμηνεία.
- Υποθέτοντας ότι κάθε κλάση ακολουθεί κανονική κατανομή με τον ίδιο πίνακα συνδιακύμανσης, η LDA προσεγγίζει τον βέλτιστο ταξινομητή κατά Bayes.
- Η
LinearDiscriminantAnalysisτου scikit-learn διευκολύνει την οπτικοποίηση ορίων απόφασης και την εξέταση των προβαλλόμενων χαρακτηριστικών.
Εισαγωγή #
Αυτή η μέθοδος πρέπει να ερμηνεύεται μέσα από τις υποθέσεις της, τις συνθήκες δεδομένων και τον τρόπο με τον οποίο οι επιλογές παραμέτρων επηρεάζουν τη γενίκευση.
Αναλυτική Επεξήγηση #
Μαθηματική Διατύπωση #
Για την περίπτωση δύο κλάσεων, η κατεύθυνση προβολής \(\mathbf{w}\) μεγιστοποιεί
$$ J(\mathbf{w}) = \frac{\mathbf{w}^\top \mathbf{S}_B \mathbf{w}}{\mathbf{w}^\top \mathbf{S}_W \mathbf{w}}, $$όπου \(\mathbf{S}_B\) είναι ο πίνακας διασποράς μεταξύ κλάσεων και \(\mathbf{S}_W\) είναι ο πίνακας διασποράς εντός κλάσεων. Στην περίπτωση πολλών κλάσεων, λαμβάνουμε έως \(K-1\) κατευθύνσεις προβολής, οι οποίες μπορούν να χρησιμοποιηθούν για μείωση διαστάσεων.
Πειράματα σε Python #
Παρακάτω εφαρμόζουμε την LDA σε ένα συνθετικό σύνολο δεδομένων δύο κλάσεων, σχεδιάζουμε το όριο απόφασης και απεικονίζουμε τα προβαλλόμενα μονοδιάστατα χαρακτηριστικά. Η κλήση της transform επιστρέφει απευθείας τα προβαλλόμενα δεδομένα.
| |
Αναφορές #
- Fisher, R. A. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7(2), 179–188.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.