2.2.3
Perceptron
Σύνοψη
- Το perceptron συγκλίνει σε πεπερασμένο αριθμό ενημερώσεων σε γραμμικά διαχωρίσιμα δεδομένα, καθιστώντας το έναν από τους παλαιότερους αλγορίθμους ταξινόμησης.
- Οι προβλέψεις χρησιμοποιούν το πρόσημο ενός σταθμισμένου αθροίσματος \(\mathbf{w}^\top \mathbf{x} + b\)· αν το πρόσημο είναι λάθος, το αντίστοιχο δείγμα ενημερώνει τα βάρη.
- Ο κανόνας ενημέρωσης — προσθήκη του λανθασμένα ταξινομημένου δείγματος κλιμακωμένου κατά τον ρυθμό μάθησης — παρέχει μια διαισθητική εισαγωγή στις μεθόδους βασισμένες σε κλίση.
- Όταν τα δεδομένα δεν είναι γραμμικά διαχωρίσιμα, απαιτείται επέκταση χαρακτηριστικών ή τεχνικές πυρήνα.
Εισαγωγή #
Αυτή η μέθοδος πρέπει να ερμηνεύεται μέσα από τις υποθέσεις της, τις συνθήκες δεδομένων και τον τρόπο με τον οποίο οι επιλογές παραμέτρων επηρεάζουν τη γενίκευση.
Αναλυτική Επεξήγηση #
Μαθηματική Διατύπωση #
Οι προβλέψεις υπολογίζονται ως
$$ \hat{y} = \operatorname{sign}(\mathbf{w}^\top \mathbf{x} + b). $$Αν ένα δείγμα \((\mathbf{x}_i, y_i)\) ταξινομηθεί λανθασμένα, ενημερώνουμε τις παραμέτρους μέσω
$$ \mathbf{w} \leftarrow \mathbf{w} + \eta\, y_i\, \mathbf{x}_i,\qquad b \leftarrow b + \eta\, y_i. $$Όταν τα δεδομένα είναι γραμμικά διαχωρίσιμα, αυτή η διαδικασία είναι εγγυημένο ότι θα συγκλίνει.
Πειράματα σε Python #
Το ακόλουθο παράδειγμα εφαρμόζει το perceptron σε συνθετικά δεδομένα, αναφέρει τον αριθμό σφαλμάτων ανά εποχή και σχεδιάζει το προκύπτον όριο απόφασης.
| |
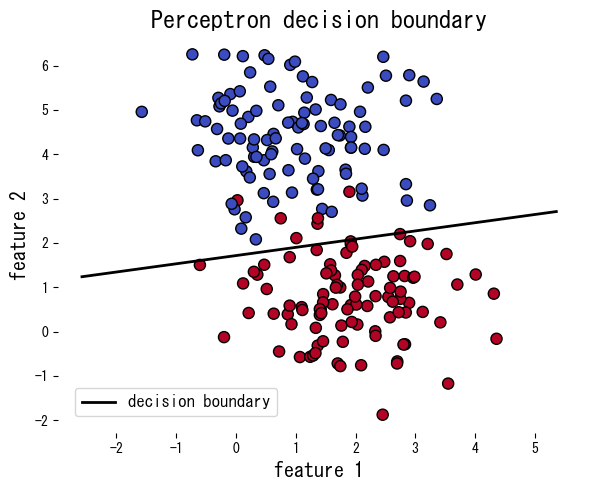
Αναφορές #
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6), 386–408.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.