2.5.4
DBSCAN
- Ο DBSCAN (Density-Based Spatial Clustering of Applications with Noise) ομαδοποιεί σημεία σύμφωνα με την τοπική πυκνότητα, ώστε οι συστάδες να μπορούν να έχουν οποιοδήποτε σχήμα, ενώ οι αραιές περιοχές γίνονται θόρυβος.
- Δύο υπερπαράμετροι ελέγχουν το μοντέλο:
eps, η ακτίνα γειτονιάς, καιmin_samples, ο ελάχιστος αριθμός γειτόνων που απαιτούνται ώστε ένα σημείο να γίνει πυρήνας. - Τα σημεία χαρακτηρίζονται ως πυρήνες, σύνορα ή θόρυβος· οι συστάδες είναι συνεκτικές συνιστώσες σημείων πυρήνα μαζί με τους γείτονες συνόρου τους.
- Μια συνηθισμένη συνταγή ρύθμισης είναι να σταθεροποιήσετε το
min_samples(≥ διαστασιμότητα + 1) και να σαρώσετε τοepsελέγχοντας το ποσοστό σημείων που επισημαίνονται ως θόρυβος.
Εισαγωγή #
Αυτή η μέθοδος πρέπει να ερμηνεύεται μέσα από τις υποθέσεις της, τις συνθήκες δεδομένων και τον τρόπο με τον οποίο οι επιλογές παραμέτρων επηρεάζουν τη γενίκευση.
Αναλυτική Επεξήγηση #
1. Επισκόπηση #
Ο DBSCAN δεν απαιτεί εκ των προτέρων τον αριθμό των συστάδων. Αντ’ αυτού, εξετάζει κάθε δείγμα:
- Σημεία πυρήνα: τουλάχιστον
min_samplesγείτονες εντός απόστασηςeps. - Σημεία συνόρου: βρίσκονται εντός της σφαίρας
epsενός σημείου πυρήνα αλλά δεν πληρούν τα ίδια το κριτήριο πυρήνα. - Σημεία θορύβου: δεν ανήκουν σε καμία γειτονιά πυρήνα.
Λόγω αυτής της οπτικής πυκνότητας, ο DBSCAN είναι ανθεκτικός σε μη κυρτές συστάδες όπως δύο μισοφέγγαρα ή ομόκεντροι κύκλοι. Πάντα κανονικοποιείτε τα χαρακτηριστικά ώστε το eps να έχει ουσιαστική ερμηνεία.
2. Τυπικός ορισμός #
Δεδομένου (x_i \in \mathcal{X}), η (\varepsilon)-γειτονιά του είναι
$$ \mathcal{N}_\varepsilon(x_i) = \{ x_j \in \mathcal{X} \mid \lVert x_i - x_j \rVert \le \varepsilon \}. $$Αν (|\mathcal{N}_\varepsilon(x_i)| \ge \texttt{min_samples}|), το σημείο είναι πυρήνας. Ο DBSCAN κατασκευάζει συστάδες εξερευνώντας σημεία προσβάσιμα μέσω πυκνότητας· ό,τι μένει ανεπίσκεπτο γίνεται θόρυβος. Με χωρικό ευρετήριο η συνολική πολυπλοκότητα είναι (O(n \log n)).
3. Παράδειγμα σε Python #
Το παρακάτω απόσπασμα χρησιμοποιεί τον DBSCAN του scikit-learn σε ένα σύνολο δεδομένων δύο μισοφέγγαρων, χρωματίζει διαφορετικά τα σημεία πυρήνα/συνόρου και αναφέρει πόσα δείγματα επισημαίνονται ως θόρυβος.
| |
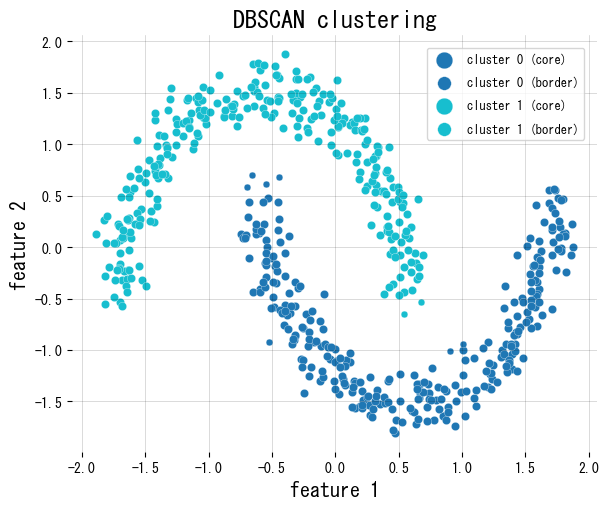
4. Πρακτικές συμβουλές #
- Σχεδιάστε τις ταξινομημένες αποστάσεις προς τον k-οστό γείτονα (k =
min_samples) για να επιλέξετε τοepsεκεί όπου η καμπύλη εμφανίζει αγκώνα. - Χρησιμοποιήστε pipelines ώστε η κανονικοποίηση και η ομαδοποίηση να εκτελούνται μαζί· διαφορετικά οι αποφάσεις βάσει απόστασης γίνονται χωρίς νόημα.
- Για πολύ μεγάλα σύνολα δεδομένων εξετάστε προσεγγιστικούς πλησιέστερους γείτονες ή μεταβείτε στον HDBSCAN, ο οποίος επεκτείνει τον DBSCAN σε δεδομένα πολλαπλής πυκνότητας και αφαιρεί την ανάγκη ρύθμισης του
eps.
5. Αναφορές #
- Ester, M., Kriegel, H.-P., Sander, J., & Xu, X. (1996). A Density-Based Algorithm for Discovering Clusters in Large Spatial Databases with Noise. KDD.
- Schubert, E., Sander, J., Ester, M., Kriegel, H.-P., & Xu, X. (2017). DBSCAN Revisited, Revisited. ACM Transactions on Database Systems.
- scikit-learn developers. (2024). Clustering. https://scikit-learn.org/stable/modules/clustering.html