2.5.5
Μοντέλα Γκαουσιανής Μίξης (GMM)
Σύνοψη
- Ένα Μοντέλο Γκαουσιανής Μίξης αναπαριστά τα δεδομένα ως σταθμισμένο άθροισμα πολυμεταβλητών κανονικών συνιστωσών.
- Παράγει έναν πίνακα ευθυνών που ποσοτικοποιεί πόσο ισχυρά κάθε συνιστώσα εξηγεί κάθε δείγμα.
- Οι παράμετροι εκτιμώνται με τον αλγόριθμο EM· οι δομές συνδιακύμανσης μπορεί να είναι
full,tied,diagήspherical. - Η επιλογή μοντέλου συνήθως συνδυάζει κριτήρια πληροφορίας (BIC/AIC) με πολλαπλές τυχαίες αρχικοποιήσεις για σταθερότητα.
Εισαγωγή #
Αυτή η μέθοδος πρέπει να ερμηνεύεται μέσα από τις υποθέσεις της, τις συνθήκες δεδομένων και τον τρόπο με τον οποίο οι επιλογές παραμέτρων επηρεάζουν τη γενίκευση.
Αναλυτική Επεξήγηση #
Μαθηματική Διατύπωση #
Η πυκνότητα του \(\mathbf{x}\) είναι
$$ p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \, \mathcal{N}(\mathbf{x} \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k), $$με βάρη μίξης \(\pi_k\) (μη αρνητικά και με άθροισμα 1). Ο EM εναλλάσσει:
- Βήμα E: υπολογισμός ευθυνών \(\gamma_{ik}\). $$ \gamma_{ik} = \frac{\pi_k \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)} {\sum_{j=1}^K \pi_j \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)}. $$
- Βήμα M: επανεκτίμηση \(\pi_k, \boldsymbol{\mu}_k, \boldsymbol{\Sigma}k\) χρησιμοποιώντας \(\gamma{ik}\) ως βάρη.
Η λογαριθμική πιθανοφάνεια αυξάνεται μονοτονικά και συγκλίνει σε τοπικό βέλτιστο.
Πειράματα σε Python #
Προσαρμόζουμε ένα GMM σε συνθετικά δισδιάστατα σύννεφα σημείων, σχεδιάζουμε τις σκληρές αναθέσεις και αναφέρουμε τα βάρη μίξης και το σχήμα του πίνακα ευθυνών.
| |
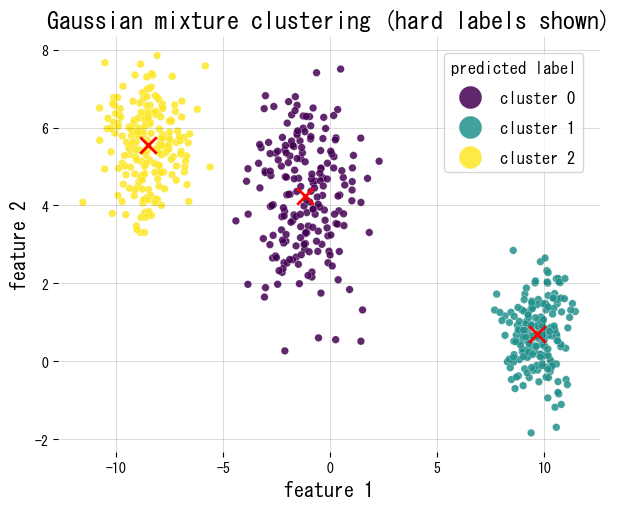
Αναφορές #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, Series B.
- scikit-learn developers. (2024). Gaussian Mixture Models. https://scikit-learn.org/stable/modules/mixture.html