Σύνοψη- Το Gradient Boosting κατασκευάζει ένα προσθετικό μοντέλο προσαρμόζοντας κάθε νέο αδύναμο εκπαιδευτή στο τρέχον υπολειπόμενο σήμα.
- Οι παράμετροι
learning_rate και n_estimators ελέγχουν από κοινού την ταχύτητα βελτιστοποίησης και τον κίνδυνο υπερπροσαρμογής. - Η επιλογή της συνάρτησης απώλειας αλλάζει την ανθεκτικότητα σε ακραίες τιμές και το σχήμα της προσαρμοσμένης συνάρτησης.
Εισαγωγή
#
Το Gradient Boosting ξεκινά με μια πρόχειρη πρόβλεψη, και στη συνέχεια προσθέτει επανειλημμένα μικρά δέντρα που διορθώνουν αυτά που το τρέχον μοντέλο εξακολουθεί να κάνει λάθος. Πολλές μικρές, στοχευμένες διορθώσεις συσσωρεύονται σε έναν ευέλικτο προβλεπτή.
Αναλυτική Επεξήγηση
#
1
2
3
4
| import numpy as np
import matplotlib.pyplot as plt
import japanize_matplotlib
from sklearn.ensemble import GradientBoostingRegressor
|
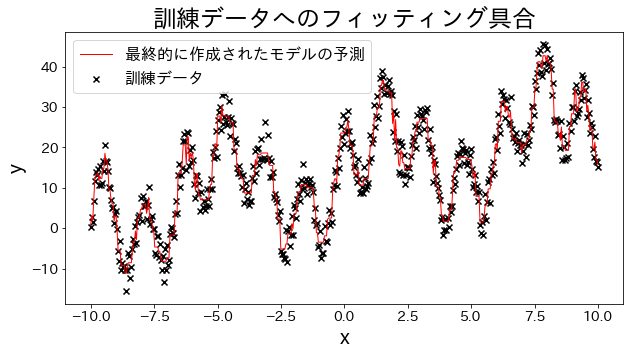
Προσαρμογή μοντέλου παλινδρόμησης στα δεδομένα εκπαίδευσης
#
Δημιουργία πειραματικών δεδομένων, δεδομένα κυματομορφής με τριγωνομετρικές συναρτήσεις αθροισμένες μαζί.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
| # training dataset
X = np.linspace(-10, 10, 500)[:, np.newaxis]
noise = np.random.rand(X.shape[0]) * 10
# target
y = (
(np.sin(X).ravel() + np.cos(4 * X).ravel()) * 10
+ 10
+ np.linspace(-10, 10, 500)
+ noise
)
# train gradient boosting
reg = GradientBoostingRegressor(
n_estimators=50,
learning_rate=0.5,
)
reg.fit(X, y)
y_pred = reg.predict(X)
# Έλεγχος προσαρμογής στα δεδομένα εκπαίδευσης
plt.figure(figsize=(10, 5))
plt.scatter(X, y, c="k", marker="x", label="training data")
plt.plot(X, y_pred, c="r", label="Predictions for the final created model", linewidth=1)
plt.xlabel("x")
plt.ylabel("y")
plt.title("Degree of fitting to training dataset")
plt.legend()
plt.show()
|
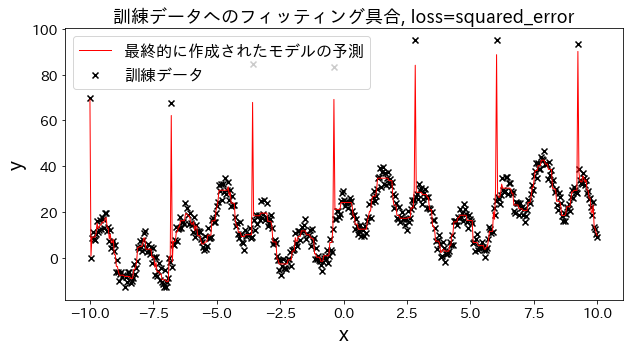
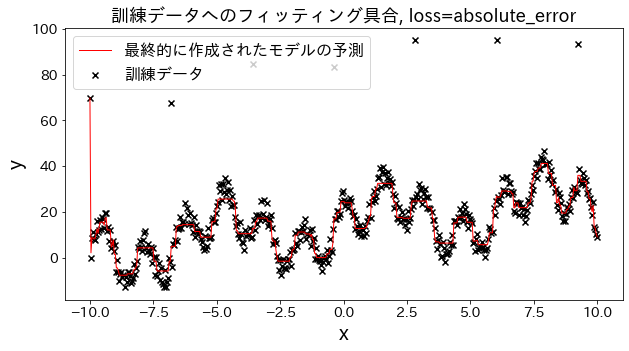
Επίδραση της συνάρτησης απώλειας στα αποτελέσματα
#
Ελέγξτε πώς αλλάζει η προσαρμογή στα δεδομένα εκπαίδευσης όταν η απώλεια αλλάζει σε [“squared_error”, “absolute_error”, “huber”, “quantile”]. Αναμένεται ότι τα “absolute_error” και “huber” δεν θα προβλέψουν τις ακραίες τιμές, δεδομένου ότι η ποινή για ακραίες τιμές δεν είναι τόσο μεγάλη όσο το τετραγωνικό σφάλμα.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
| # training data
X = np.linspace(-10, 10, 500)[:, np.newaxis]
# prepare outliers
noise = np.random.rand(X.shape[0]) * 10
for i, ni in enumerate(noise):
if i % 80 == 0:
noise[i] = 70 + np.random.randint(-10, 10)
# target
y = (
(np.sin(X).ravel() + np.cos(4 * X).ravel()) * 10
+ 10
+ np.linspace(-10, 10, 500)
+ noise
)
for loss in ["squared_error", "absolute_error", "huber", "quantile"]:
# train gradient boosting
reg = GradientBoostingRegressor(
n_estimators=50,
learning_rate=0.5,
loss=loss,
)
reg.fit(X, y)
y_pred = reg.predict(X)
# Έλεγχος προσαρμογής στα δεδομένα εκπαίδευσης.
plt.figure(figsize=(10, 5))
plt.scatter(X, y, c="k", marker="x", label="training dataset")
plt.plot(X, y_pred, c="r", label="Predictions for the final created model", linewidth=1)
plt.xlabel("x")
plt.ylabel("y")
plt.title(f"Degree of fitting to training data, loss={loss}", fontsize=18)
plt.legend()
plt.show()
|
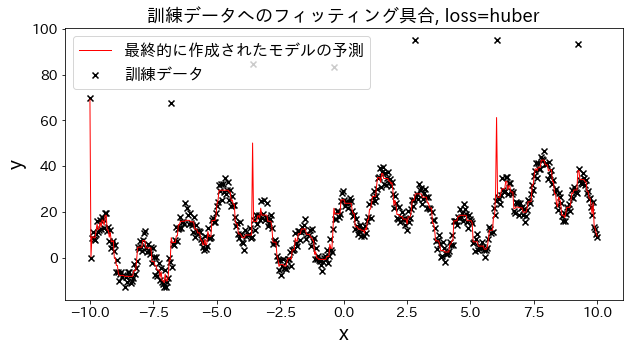
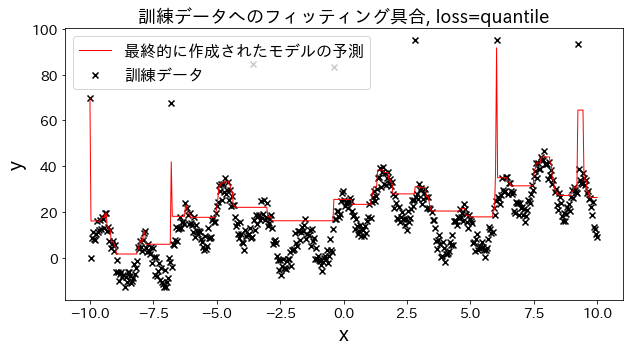
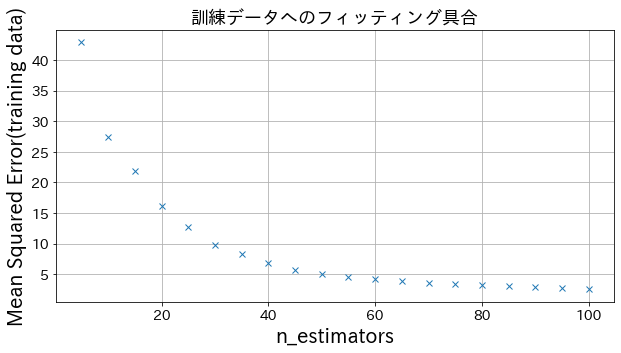
Επίδραση του n_estimators στα αποτελέσματα
#
Μπορείτε να δείτε πώς ο βαθμός βελτίωσης φτάνει σε ένα σημείο κορεσμού όταν αυξήσετε αρκετά το n_estimators.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
| from sklearn.metrics import mean_squared_error as MSE
# trainig dataset
X = np.linspace(-10, 10, 500)[:, np.newaxis]
noise = np.random.rand(X.shape[0]) * 10
# target
y = (
(np.sin(X).ravel() + np.cos(4 * X).ravel()) * 10
+ 10
+ np.linspace(-10, 10, 500)
+ noise
)
# Δοκιμή δημιουργίας μοντέλου με διαφορετικά n_estimators
n_estimators_list = [(i + 1) * 5 for i in range(20)]
mses = []
for n_estimators in n_estimators_list:
reg = GradientBoostingRegressor(
n_estimators=n_estimators,
learning_rate=0.3,
)
reg.fit(X, y)
y_pred = reg.predict(X)
mses.append(MSE(y, y_pred))
# Σχεδίαση mean_squared_error για διαφορετικά n_estimators
plt.figure(figsize=(10, 5))
plt.plot(n_estimators_list, mses, "x")
plt.xlabel("n_estimators")
plt.ylabel("Mean Squared Error(training data)")
plt.grid()
plt.show()
|
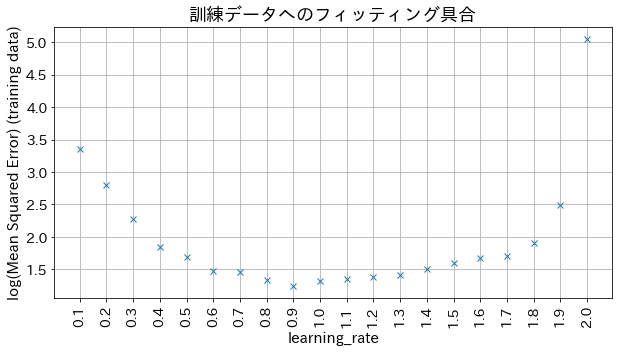
Επίδραση του learning_rate στα αποτελέσματα
#
Αν το learning_rate είναι πολύ μικρό, η ακρίβεια δεν βελτιώνεται, και αν το learning_rate είναι πολύ μεγάλο, δεν συγκλίνει.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
| # Δοκιμή δημιουργίας μοντέλου με διαφορετικά n_estimators
learning_rate_list = [np.round(0.1 * (i + 1), 1) for i in range(20)]
mses = []
for learning_rate in learning_rate_list:
reg = GradientBoostingRegressor(
n_estimators=30,
learning_rate=learning_rate,
)
reg.fit(X, y)
y_pred = reg.predict(X)
mses.append(np.log(MSE(y, y_pred)))
# Σχεδίαση mean_squared_error για διαφορετικά n_estimators
plt.figure(figsize=(10, 5))
plt_index = [i for i in range(len(learning_rate_list))]
plt.plot(plt_index, mses, "x")
plt.xticks(plt_index, learning_rate_list, rotation=90)
plt.xlabel("learning_rate", fontsize=15)
plt.ylabel("log(Mean Squared Error) (training data)", fontsize=15)
plt.grid()
plt.show()
|