2.1.6
Μπεϋζιανή Γραμμική Παλινδρόμηση
- Η Μπεϋζιανή γραμμική παλινδρόμηση αντιμετωπίζει τους συντελεστές ως τυχαίες μεταβλητές, εκτιμώντας τόσο τις προβλέψεις όσο και την αβεβαιότητά τους.
- Η εκ των υστέρων κατανομή προκύπτει αναλυτικά από την εκ των προτέρων κατανομή και την πιθανοφάνεια, καθιστώντας τη μέθοδο ανθεκτική για μικρά ή θορυβώδη σύνολα δεδομένων.
- Η προβλεπτική κατανομή είναι Γκαουσιανή, οπότε ο μέσος και η διακύμανσή της μπορούν να οπτικοποιηθούν και να χρησιμοποιηθούν για λήψη αποφάσεων.
- Το
BayesianRidgeστο scikit-learn ρυθμίζει αυτόματα τη διακύμανση θορύβου, απλοποιώντας την πρακτική εφαρμογή.
Εισαγωγή #
Αυτή η μέθοδος πρέπει να ερμηνεύεται μέσα από τις υποθέσεις της, τις συνθήκες των δεδομένων και τον τρόπο με τον οποίο οι επιλογές παραμέτρων επηρεάζουν τη γενίκευση.
Αναλυτική Επεξήγηση #
Μαθηματική Διατύπωση #
Υποθέτουμε πολυμεταβλητή Γκαουσιανή εκ των προτέρων κατανομή με μέσο 0 και διακύμανση \(\tau^{-1}\) για το διάνυσμα συντελεστών \(\boldsymbol\beta\), και Γκαουσιανό θόρυβο \(\epsilon_i \sim \mathcal{N}(0, \alpha^{-1})\) στις παρατηρήσεις. Η εκ των υστέρων κατανομή γίνεται
$$ p(\boldsymbol\beta \mid \mathbf{X}, \mathbf{y}) = \mathcal{N}(\boldsymbol\beta \mid \boldsymbol\mu, \mathbf{\Sigma}) $$με
$$ \mathbf{\Sigma} = (\alpha \mathbf{X}^\top \mathbf{X} + \tau \mathbf{I})^{-1}, \qquad \boldsymbol\mu = \alpha \mathbf{\Sigma} \mathbf{X}^\top \mathbf{y}. $$Η προβλεπτική κατανομή για μια νέα είσοδο \(\mathbf{x}*\) είναι επίσης Γκαουσιανή, \(\mathcal{N}(\hat{y}, \sigma_^2)\). Το BayesianRidge εκτιμά τα \(\alpha\) και \(\tau\) από τα δεδομένα, ώστε να μπορείτε να χρησιμοποιήσετε το μοντέλο χωρίς χειροκίνητη ρύθμιση.
Πειράματα σε Python #
Το ακόλουθο παράδειγμα συγκρίνει τη μέθοδο ελαχίστων τετραγώνων με τη Μπεϋζιανή γραμμική παλινδρόμηση σε δεδομένα που περιέχουν ακραίες τιμές.
| |
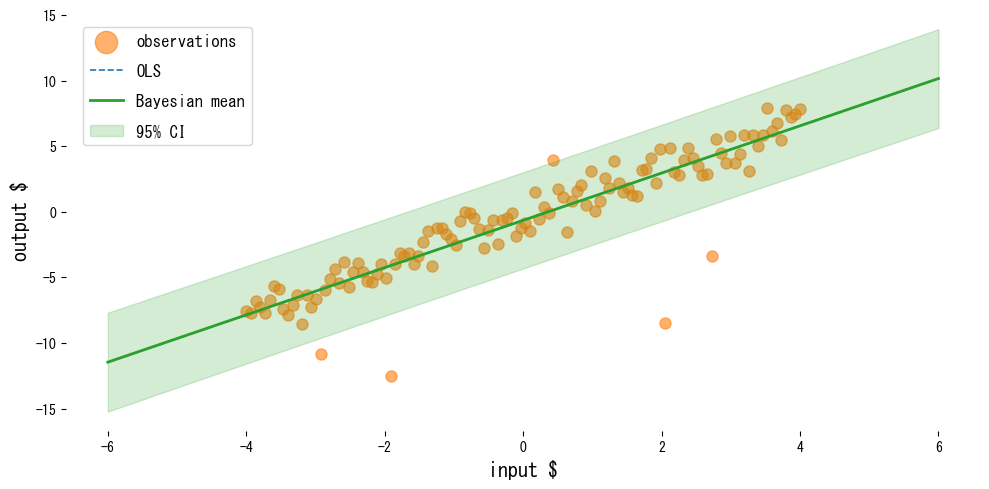
Ανάγνωση των αποτελεσμάτων #
- Η μέθοδος ελαχίστων τετραγώνων έλκεται προς τις ακραίες τιμές, ενώ η Μπεϋζιανή γραμμική παλινδρόμηση διατηρεί τη μέση πρόβλεψη πιο σταθερή.
- Χρησιμοποιώντας
return_std=Trueλαμβάνουμε την τυπική απόκλιση πρόβλεψης, η οποία διευκολύνει τη σχεδίαση διαστημάτων αξιοπιστίας. - Η εξέταση της εκ των υστέρων διακύμανσης αναδεικνύει ποιοι συντελεστές φέρουν τη μεγαλύτερη αβεβαιότητα.
Αναφορές #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.