2.1.4
Πολυωνυμική Παλινδρόμηση
Σύνοψη
- Η πολυωνυμική παλινδρόμηση επεκτείνει τα χαρακτηριστικά με δυνάμεις ώστε ένα γραμμικό μοντέλο να μπορεί να προσαρμοστεί σε μη γραμμικές σχέσεις.
- Το μοντέλο παραμένει γραμμικός συνδυασμός συντελεστών, διατηρώντας λύσεις κλειστής μορφής και ερμηνευσιμότητα.
- Υψηλότεροι βαθμοί αυξάνουν την εκφραστικότητα αλλά προκαλούν επίσης υπερπροσαρμογή, καθιστώντας σημαντικές την κανονικοποίηση και τη διασταυρωμένη επικύρωση.
- Η τυποποίηση των χαρακτηριστικών και η ρύθμιση του βαθμού μαζί με την ισχύ ποινής οδηγούν σε σταθερές προβλέψεις.
Εισαγωγή #
Αυτή η μέθοδος πρέπει να ερμηνεύεται μέσα από τις υποθέσεις της, τις συνθήκες των δεδομένων και τον τρόπο με τον οποίο οι επιλογές παραμέτρων επηρεάζουν τη γενίκευση.
Αναλυτική Επεξήγηση #
Μαθηματική Διατύπωση #
Δεδομένου \(\mathbf{x} = (x_1, \dots, x_m)\), κατασκευάζουμε ένα πολυωνυμικό διάνυσμα χαρακτηριστικών \(\phi(\mathbf{x})\) μέχρι βαθμό \(d\) και εφαρμόζουμε γραμμική παλινδρόμηση. Για \(m = 2\) και \(d = 2\),
$$ \phi(\mathbf{x}) = (1, x_1, x_2, x_1^2, x_1 x_2, x_2^2), $$και το μοντέλο γίνεται
$$ y = \mathbf{w}^\top \phi(\mathbf{x}). $$Καθώς το \(d\) αυξάνεται, ο αριθμός των όρων αυξάνεται ραγδαία, οπότε στην πράξη ξεκινάμε με βαθμό 2 ή 3 και τον συνδυάζουμε με κανονικοποίηση (π.χ., Ridge) όταν χρειάζεται.
Πειράματα σε Python #
Παρακάτω προσθέτουμε πολυωνυμικά χαρακτηριστικά τρίτου βαθμού και προσαρμόζουμε μια καμπύλη σε δεδομένα που δημιουργήθηκαν από κυβική συνάρτηση με θόρυβο.
| |
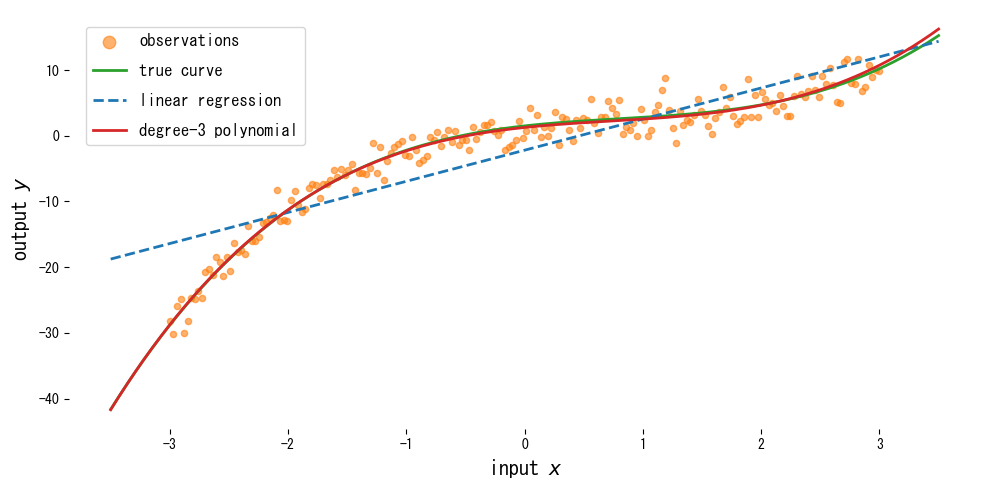
Ανάγνωση των αποτελεσμάτων #
- Η απλή γραμμική παλινδρόμηση χάνει την καμπυλότητα, ειδικά κοντά στο κέντρο, ενώ το κυβικό πολυώνυμο ακολουθεί στενά την πραγματική καμπύλη.
- Η αύξηση του βαθμού βελτιώνει την προσαρμογή στα δεδομένα εκπαίδευσης αλλά μπορεί να κάνει την εξωγραμμική πρόβλεψη ασταθή.
- Ο συνδυασμός πολυωνυμικών χαρακτηριστικών με κανονικοποιημένη παλινδρόμηση (π.χ., Ridge) μέσω pipeline βοηθά στον περιορισμό της υπερπροσαρμογής.
Αναφορές #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.