2.1.7
Παλινδρόμηση Ποσοστημορίων
Σύνοψη
- Η παλινδρόμηση ποσοστημορίων εκτιμά απευθείας αυθαίρετα ποσοστημόρια — όπως τη διάμεσο ή το 10ο εκατοστημόριο — αντί μόνο του μέσου.
- Η ελαχιστοποίηση της απώλειας pinball προσφέρει ανθεκτικότητα σε ακραίες τιμές και διαχειρίζεται ασύμμετρο θόρυβο.
- Ανεξάρτητα μοντέλα μπορούν να προσαρμοστούν για διαφορετικά ποσοστημόρια, και ο συνδυασμός τους σχηματίζει διαστήματα πρόβλεψης.
- Η κλιμάκωση χαρακτηριστικών και η κανονικοποίηση βοηθούν στη σταθεροποίηση της σύγκλισης και τη διατήρηση της γενίκευσης.
Εισαγωγή #
Αυτή η μέθοδος πρέπει να ερμηνεύεται μέσα από τις υποθέσεις της, τις συνθήκες των δεδομένων και τον τρόπο με τον οποίο οι επιλογές παραμέτρων επηρεάζουν τη γενίκευση.
Αναλυτική Επεξήγηση #
Μαθηματική Διατύπωση #
Με υπόλοιπο \(r = y - \hat{y}\) και επίπεδο ποσοστημορίου \(\tau \in (0, 1)\), η απώλεια pinball ορίζεται ως
$$ L_\tau(r) = \begin{cases} \tau r & (r \ge 0) \\ (\tau - 1) r & (r < 0) \end{cases} $$Η ελαχιστοποίηση αυτής της απώλειας δίνει έναν γραμμικό προβλεπτή για το \(\tau\)-ποσοστημόριο. Θέτοντας \(\tau = 0.5\) ανακτούμε τη διάμεσο και καταλήγουμε στην ίδια λύση με την παλινδρόμηση ελαχίστων απόλυτων αποκλίσεων.
Πειράματα σε Python #
Χρησιμοποιούμε τον QuantileRegressor για να εκτιμήσουμε τα ποσοστημόρια 0.1, 0.5 και 0.9 και τα συγκρίνουμε με τη μέθοδο ελαχίστων τετραγώνων.
| |
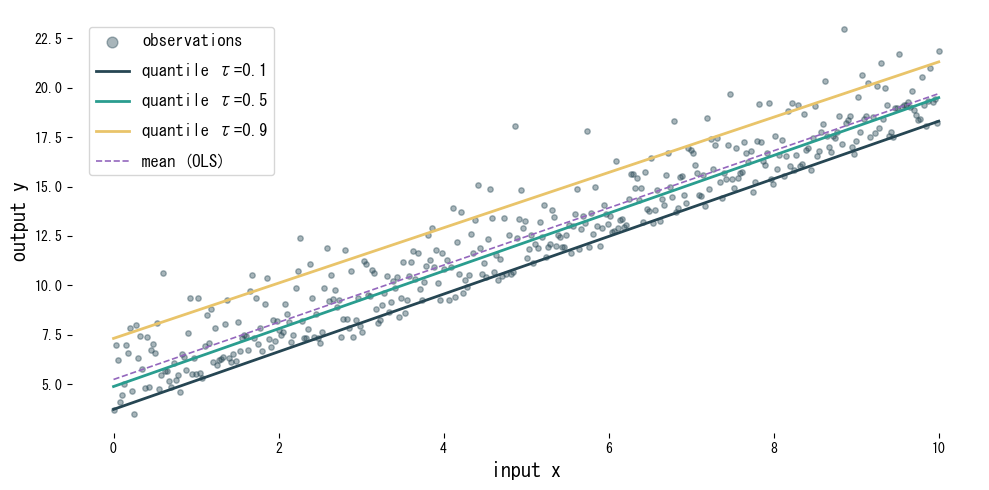
Ανάγνωση των αποτελεσμάτων #
- Κάθε ποσοστημόριο παράγει μια διαφορετική ευθεία, αποτυπώνοντας την κατακόρυφη εξάπλωση των δεδομένων.
- Σε σύγκριση με το μοντέλο OLS που εστιάζει στον μέσο, η παλινδρόμηση ποσοστημορίων προσαρμόζεται σε ασύμμετρο θόρυβο.
- Ο συνδυασμός πολλαπλών ποσοστημορίων δίνει διαστήματα πρόβλεψης που μεταφέρουν αβεβαιότητα σχετική με τη λήψη αποφάσεων.
Αναφορές #
- Koenker, R., & Bassett, G. (1978). Regression Quantiles. Econometrica, 46(1), 33–50.
- Koenker, R. (2005). Quantile Regression. Cambridge University Press.