2.3.1
Δέντρο Απόφασης (Ταξινομητής)
- Ένας ταξινομητής δέντρου απόφασης διαχωρίζει τον χώρο χαρακτηριστικών με μια ακολουθία ερωτήσεων αν-τότε, ώστε κάθε τερματικός κόμβος να περιέχει κυρίως μία κλάση.
- Η ποιότητα διαχωρισμού μετράται με δείκτες ακαθαρσίας όπως ο δείκτης Gini ή η εντροπία· επιλέξτε τον δείκτη που αντικατοπτρίζει καλύτερα το κόστος λανθασμένης ταξινόμησης για την εργασία σας.
- Ο έλεγχος του βάθους, του ελάχιστου αριθμού δειγμάτων ανά κόμβο ή το κλάδεμα εμποδίζουν το δέντρο να απομνημονεύσει θόρυβο, διατηρώντας παράλληλα την ερμηνευσιμότητα.
- Η οπτικοποίηση τόσο των περιοχών απόφασης όσο και του μαθημένου δέντρου βοηθά στην εξήγηση του μοντέλου στους ενδιαφερόμενους.
Εισαγωγή #
Αυτή η μέθοδος θα πρέπει να ερμηνεύεται μέσω των υποθέσεών της, των συνθηκών δεδομένων και του τρόπου με τον οποίο οι επιλογές παραμέτρων επηρεάζουν τη γενίκευση.
Αναλυτική Επεξήγηση #
1. Επισκόπηση #
Τα δέντρα απόφασης είναι μοντέλα εποπτευόμενης μάθησης που διαχωρίζουν αναδρομικά τον χώρο εισόδου. Ξεκινώντας από τη ρίζα, κάθε εσωτερικός κόμβος θέτει μια ερώτηση όπως “είναι (x_j \le s);” και δρομολογεί το δείγμα στον επόμενο κόμβο. Για την ταξινόμηση θέλουμε φύλλα όσο το δυνατόν πιο καθαρά, δηλαδή να περιέχουν σχεδόν μόνο μία ετικέτα κλάσης. Το τελικό μοντέλο είναι επομένως ένα συμπαγές βιβλίο κανόνων που μπορεί εύκολα να επιθεωρηθεί ή να μετατραπεί σε επιχειρηματική λογική.
2. Μέτρα ακαθαρσίας #
Έστω (t) ένας κόμβος και (p_k) η αναλογία κλάσης μέσα σε αυτόν τον κόμβο. Δύο συνηθισμένοι δείκτες ακαθαρσίας είναι
$$ \mathrm{Gini}(t) = 1 - \sum_k p_k^2, $$$$ H(t) = - \sum_k p_k \log p_k. $$Κατά τον διαχωρισμό του κόμβου (t) στο χαρακτηριστικό (x_j) με κατώφλι (s), αξιολογούμε το κέρδος
$$ \Delta I = I(t) - \frac{n_L}{n_t} I(t_L) - \frac{n_R}{n_t} I(t_R), $$όπου (I(\cdot)) είναι είτε ο δείκτης Gini είτε η εντροπία, (t_L) και (t_R) είναι οι θυγατρικοί κόμβοι, και (n_t) είναι ο αριθμός δειγμάτων που φτάνουν στο (t). Επιλέγεται ο διαχωρισμός που μεγιστοποιεί το (\Delta I).
3. Παράδειγμα σε Python #
Το παρακάτω απόσπασμα κώδικα δημιουργεί ένα σύνολο δεδομένων δύο κλάσεων με τη make_classification, εκπαιδεύει έναν DecisionTreeClassifier και οπτικοποιεί τις περιοχές απόφασής του. Αλλάζοντας το criterion από "gini" σε "entropy" εναλλάσσεται το μέτρο ακαθαρσίας.
| |
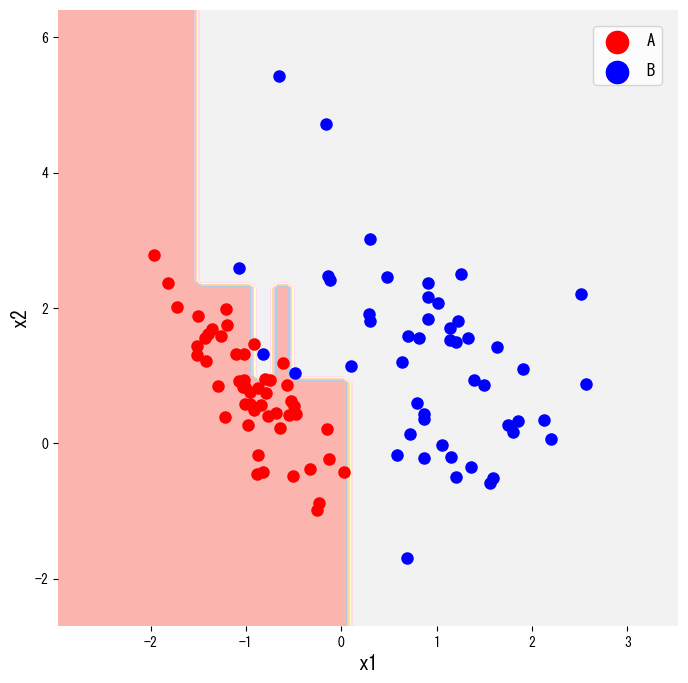
Ο ίδιος εκτιμητής μπορεί να αποδοθεί ως πραγματικό διάγραμμα δέντρου με τη plot_tree, κάτι που είναι βολικό για αναφορές ή παρουσιάσεις.
| |

4. Αναφορές #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html