2.2.7
k-Nearest Neighbours (k-NN)
Summary
- k-NN stores the training data and predicts by majority vote among the \(k\) nearest neighbours of a query point.
- The main hyperparameters are the number of neighbours \(k\) and the distance weighting scheme, which are easy to tune.
- It naturally models non-linear decision boundaries, but distance metrics become less informative in high dimensions (“the curse of dimensionality”).
- Standardising features or selecting informative ones makes distance calculations more stable.
Intuition #
This method should be interpreted through its assumptions, data conditions, and how parameter choices affect generalization.
Detailed Explanation #
Mathematical formulation #
For a test point \(\mathbf{x}\), let \(\mathcal{N}_k(\mathbf{x})\) be the set of \(k\) nearest neighbours in the training set. The vote for class \(c\) is
$$ v_c = \sum_{i \in \mathcal{N}_k(\mathbf{x})} w_i \,\mathbb{1}(y_i = c), $$where the weights \(w_i\) can be uniform or a function of distance (e.g. inverse distance). The predicted class is the one with the highest vote.
Experiments with Python #
The following Python snippet evaluates several neighbour counts on a train/validation split and plots the decision regions for the best-performing model.
| |
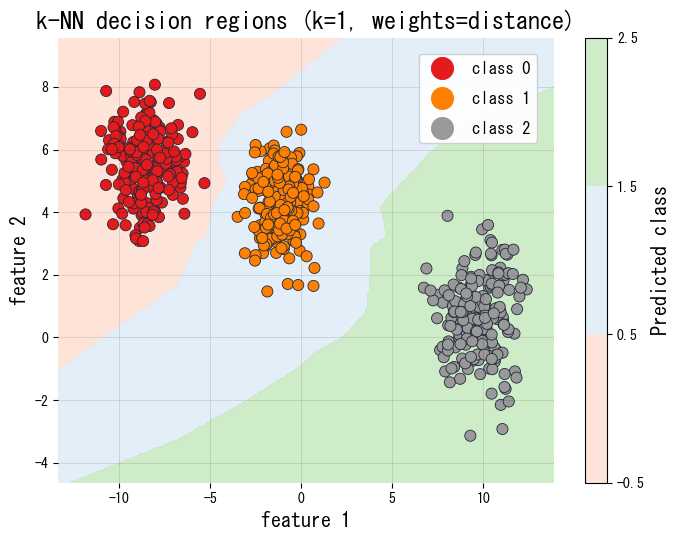
References #
- Cover, T. M., & Hart, P. E. (1967). Nearest Neighbor Pattern Classification. IEEE Transactions on Information Theory, 13(1), 21–27.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.