2.2.1
Logistic Regression
Summary
- Logistic regression passes a linear combination of the inputs through the sigmoid function to predict the probability that the label is 1.
- The output lives in \([0, 1]\), so you can set decision thresholds flexibly and interpret coefficients as contributions to the log-odds.
- Training minimises the cross-entropy loss (equivalently maximises the log-likelihood); L1/L2 regularisation keeps the model from overfitting.
- scikit-learn’s
LogisticRegressionhandles preprocessing, training, and decision-boundary visualisation with a few lines of code.
Intuition #
This method should be interpreted through its assumptions, data conditions, and how parameter choices affect generalization.
Detailed Explanation #
Mathematical formulation #
The probability of class 1 given \(\mathbf{x}\) is
$$ P(y=1 \mid \mathbf{x}) = \sigma(\mathbf{w}^\top \mathbf{x} + b) = \frac{1}{1 + \exp\left(-(\mathbf{w}^\top \mathbf{x} + b)\right)}. $$Learning maximises the log-likelihood
$$ \ell(\mathbf{w}, b) = \sum_{i=1}^{n} \Bigl[ y_i \log p_i + (1 - y_i) \log (1 - p_i) \Bigr], \quad p_i = \sigma(\mathbf{w}^\top \mathbf{x}_i + b), $$or equivalently minimises the negative cross-entropy loss. Adding L2 regularisation keeps coefficients from exploding, while L1 regularisation can drive irrelevant weights all the way to zero.
Experiments with Python #
The snippet below fits logistic regression to a synthetic two-dimensional data set and visualises the resulting decision boundary. Everything—from training to plotting—fits in a few lines thanks to scikit-learn.
| |
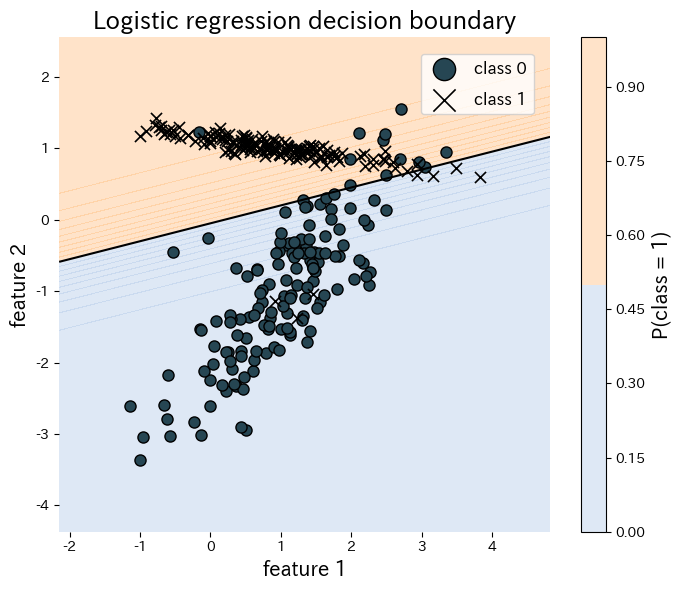
References #
- Agresti, A. (2015). Foundations of Linear and Generalized Linear Models. Wiley.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.