2.2.3
Perceptron
Summary
- The perceptron converges in a finite number of updates on linearly separable data, making it one of the oldest classification algorithms.
- Predictions use the sign of a weighted sum \(\mathbf{w}^\top \mathbf{x} + b\); if the sign is wrong, the corresponding sample updates the weights.
- The update rule—adding the misclassified sample scaled by the learning rate—provides an intuitive introduction to gradient-based methods.
- When data are not linearly separable, feature expansion or kernel tricks are needed.
- Logistic Regression — understanding this concept first will make learning smoother
Intuition #
This method should be interpreted through its assumptions, data conditions, and how parameter choices affect generalization.
Detailed Explanation #
Mathematical formulation #
Predictions are computed as
$$ \hat{y} = \operatorname{sign}(\mathbf{w}^\top \mathbf{x} + b). $$If a sample \((\mathbf{x}_i, y_i)\) is misclassified, update the parameters via
$$ \mathbf{w} \leftarrow \mathbf{w} + \eta\, y_i\, \mathbf{x}_i,\qquad b \leftarrow b + \eta\, y_i. $$When the data are linearly separable, this procedure is guaranteed to converge.
Experiments with Python #
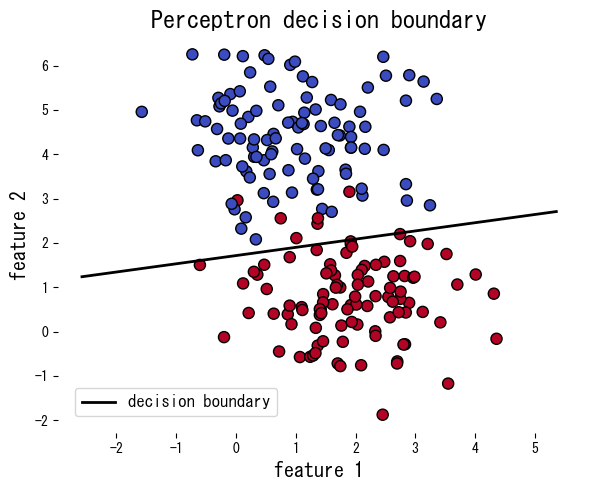
The following example applies the perceptron to synthetic data, reporting the number of mistakes per epoch and plotting the resulting decision boundary.
| |
References #
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6), 386–408.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.