2.2.2
Softmax Regression
Summary
- Softmax regression generalises logistic regression to multiple classes, producing the probability of every class simultaneously.
- Outputs lie in \([0, 1]\) and sum to 1, so they plug directly into decision thresholds, cost-sensitive rules, or downstream pipelines.
- Training minimises the cross-entropy loss, directly correcting discrepancies between predicted and true probability distributions.
- In scikit-learn,
LogisticRegression(multi_class="multinomial")implements softmax regression and supports L1/L2 regularisation.
- Logistic Regression — understanding this concept first will make learning smoother
Intuition #
This method should be interpreted through its assumptions, data conditions, and how parameter choices affect generalization.
Detailed Explanation #
Mathematical formulation #
Let \(K\) be the number of classes, \(\mathbf{w}_k\) and \(b_k\) the parameters for class \(k\). Then
$$ P(y = k \mid \mathbf{x}) = \frac{\exp\left(\mathbf{w}_k^\top \mathbf{x} + b_k\right)} {\sum_{j=1}^{K} \exp\left(\mathbf{w}_j^\top \mathbf{x} + b_j\right)}. $$The objective is the cross-entropy loss
$$ L = - \sum_{i=1}^{n} \sum_{k=1}^{K} \mathbb{1}(y_i = k) \log P(y = k \mid \mathbf{x}_i), $$with optional regularisation on the weights to prevent overfitting.
Experiments with Python #
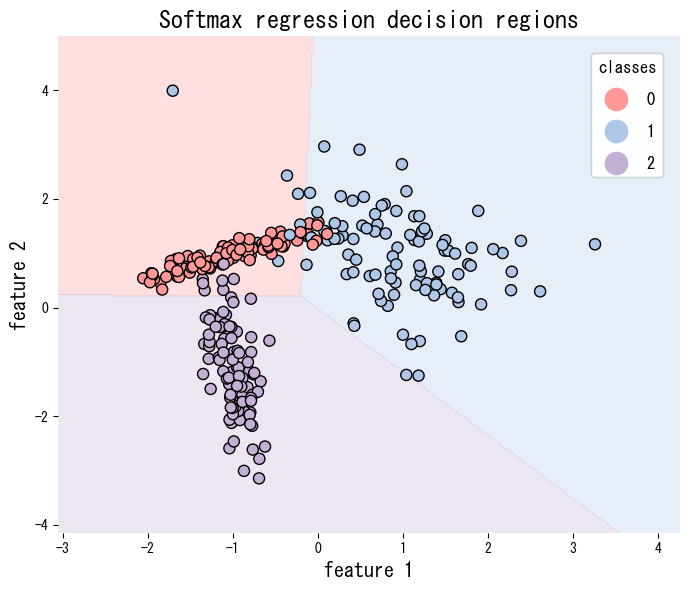
The script below applies softmax regression to a synthetic three-class data set and visualises the decision regions. Setting multi_class="multinomial" activates the softmax formulation.
| |
References #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.