2.2.5
Support Vector Machines (SVM)
Summary
- SVM learns a decision boundary that maximises the margin between classes, emphasising generalisation.
- Soft margins introduce slack variables so that some misclassifications are allowed while the penalty \(C\) balances margin width and errors.
- Kernel tricks replace dot products with kernel functions, enabling non-linear decision boundaries without explicit feature expansion.
- Feature standardisation and hyperparameter tuning (e.g. \(C\), \(\gamma\)) are crucial for good performance.
- Logistic Regression — understanding this concept first will make learning smoother
Intuition #
This method should be interpreted through its assumptions, data conditions, and how parameter choices affect generalization.
Detailed Explanation #
Mathematical formulation #
For linearly separable data we solve
$$ \min_{\mathbf{w}, b} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1. $$In practice we use the soft-margin variant with slack variables \(\xi_i \ge 0\):
$$ \min_{\mathbf{w}, b, \boldsymbol{\xi}} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 + C \sum_{i=1}^{n} \xi_i \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1 - \xi_i. $$Replacing inner products \(\mathbf{x}_i^\top \mathbf{x}_j\) with kernels \(K(\mathbf{x}_i, \mathbf{x}_j)\) yields non-linear decision boundaries.
Experiments with Python #
The code below fits SVM with a linear kernel and with an RBF kernel on a non-linearly separable data set generated by make_moons. The RBF kernel captures the curved boundary much better.
| |
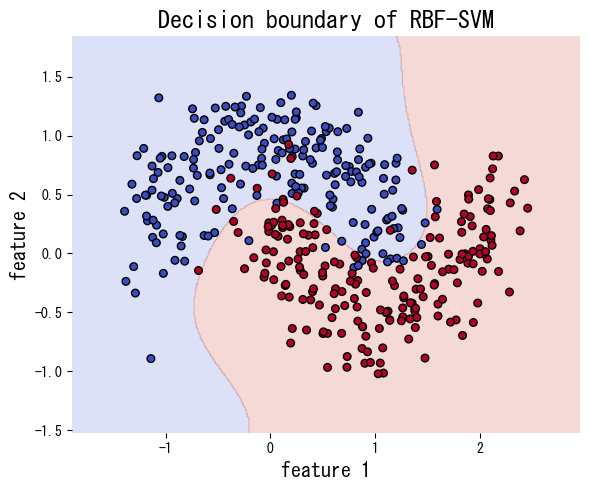
References #
- Vapnik, V. (1998). Statistical Learning Theory. Wiley.
- Smola, A. J., & Schölkopf, B. (2004). A Tutorial on Support Vector Regression. Statistics and Computing, 14(3), 199–222.