2.4.3
Adaboost (classification)
Summary- AdaBoost classification sequentially trains weak learners while increasing weights on misclassified samples.
learning_rate and n_estimators control the bias-variance trade-off and convergence behavior.- Using shallow trees as base learners allows the ensemble to progressively correct difficult decision regions.
Intuition
#
AdaBoost works by repeatedly focusing on mistakes from the previous round. Each weak learner is limited, but the weighted ensemble accumulates complementary corrections, producing a strong classifier from simple components.
Detailed Explanation
#
1
2
3
4
5
6
7
8
9
| import matplotlib.pyplot as plt
import japanize_matplotlib
import numpy as np
from sklearn.datasets import make_classification
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from sklearn.tree import DecisionTreeClassifier
from sklearn.ensemble import AdaBoostClassifier
|
Create data for experiment
#
1
2
3
4
5
6
7
8
9
10
11
12
| n_features = 20
X, y = make_classification(
n_samples=2500,
n_features=n_features,
n_informative=10,
n_classes=2,
n_redundant=4,
n_clusters_per_class=5,
)
X_train, X_test, y_train, y_test = train_test_split(
X, y, test_size=0.33, random_state=42
)
|
Train adaboost
#
Here we use a decision tree as a weak learner.
1
2
3
4
5
6
7
8
9
10
11
12
| ab_clf = AdaBoostClassifier(
n_estimators=10,
learning_rate=1.0,
random_state=117117,
base_estimator=DecisionTreeClassifier(max_depth=2),
)
ab_clf.fit(X_train, y_train)
y_pred = ab_clf.predict(X_test)
ab_clf_score = roc_auc_score(y_test, y_pred)
ab_clf_score
|
0.7546477034876885
Influence of learning-rate
#
The smaller the learning-rate, the smaller the range of weight updates. Conversely, if it is too large, convergence may not occur.
1
2
3
4
5
6
7
8
9
10
11
12
13
| scores = []
learning_rate_list = np.linspace(0.01, 1, 100)
for lr in learning_rate_list:
ab_clf_i = AdaBoostClassifier(
n_estimators=10,
learning_rate=lr,
random_state=117117,
base_estimator=DecisionTreeClassifier(max_depth=2),
)
ab_clf_i.fit(X_train, y_train)
y_pred = ab_clf_i.predict(X_test)
scores.append(roc_auc_score(y_test, y_pred))
|
1
2
3
4
5
6
| plt.figure(figsize=(5, 5))
plt.plot(learning_rate_list, scores)
plt.xlabel("learning rate")
plt.ylabel("ROC-AUC")
plt.grid()
plt.show()
|
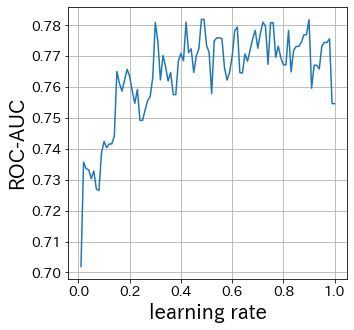
Influence of n_estimators
#
N_estimators specifies the number of weak learners.
Normally, there is no need to make this parameter larger or smaller.
Fix n_estimators at some large number and then adjust the other parameters.
1
2
3
4
5
6
7
8
9
10
11
12
13
| scores = []
n_estimators_list = [int(ne) for ne in np.linspace(5, 70, 40)]
for n_estimators in n_estimators_list:
ab_clf_i = AdaBoostClassifier(
n_estimators=int(n_estimators),
learning_rate=0.6,
random_state=117117,
base_estimator=DecisionTreeClassifier(max_depth=2),
)
ab_clf_i.fit(X_train, y_train)
y_pred = ab_clf_i.predict(X_test)
scores.append(roc_auc_score(y_test, y_pred))
|
1
2
3
4
5
6
| plt.figure(figsize=(5, 5))
plt.plot(n_estimators_list, scores)
plt.xlabel("n_estimators")
plt.ylabel("ROC-AUC")
plt.grid()
plt.show()
|
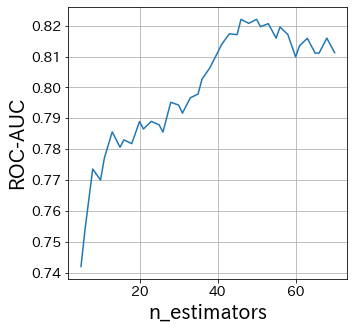
Influence of base-estimator
#
base_estimator specifies what to use as a weak learner. In other words, it is one of the most important parameters in Adaboost.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
| scores = []
base_estimator_list = [
DecisionTreeClassifier(max_depth=md) for md in [2, 3, 4, 5, 6, 7, 8, 9, 10]
]
for base_estimator in base_estimator_list:
ab_clf_i = AdaBoostClassifier(
n_estimators=10,
learning_rate=0.5,
random_state=117117,
base_estimator=base_estimator,
)
ab_clf_i.fit(X_train, y_train)
y_pred = ab_clf_i.predict(X_test)
scores.append(roc_auc_score(y_test, y_pred))
|
1
2
3
4
5
6
7
| plt.figure(figsize=(5, 5))
plt_index = [i for i in range(len(base_estimator_list))]
plt.bar(plt_index, scores)
plt.xticks(plt_index, [str(bm) for bm in base_estimator_list], rotation=90)
plt.xlabel("base_estimator")
plt.ylabel("ROC-AUC")
plt.show()
|

Visualization of data weights in Adaboost
#
Visualize assigning weights to data that is difficult to classify.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
| # NOTE: Model created to check the sample_weight passed to the model
# This DummyClassifier does not change the parameters of the Adaboost
class DummyClassifier:
def __init__(self):
self.model = DecisionTreeClassifier(max_depth=3)
self.n_classes_ = 2
self.classes_ = ["A", "B"]
self.sample_weight = None ## sample_weight
def fit(self, X, y, sample_weight=None):
self.sample_weight = sample_weight
self.model.fit(X, y, sample_weight=sample_weight)
return self.model
def predict(self, X, check_input=True):
proba = self.model.predict(X)
return proba
def get_params(self, deep=False):
return {}
def set_params(self, deep=False):
return {}
n_samples = 500
X_2, y_2 = make_classification(
n_samples=n_samples,
n_features=2,
n_informative=2,
n_redundant=0,
n_repeated=0,
random_state=117,
n_clusters_per_class=2,
)
plt.figure(
figsize=(
7,
7,
)
)
plt.title(f"Scatter plots of sample data")
plt.scatter(X_2[:, 0], X_2[:, 1], c=y_2)
plt.show()
|
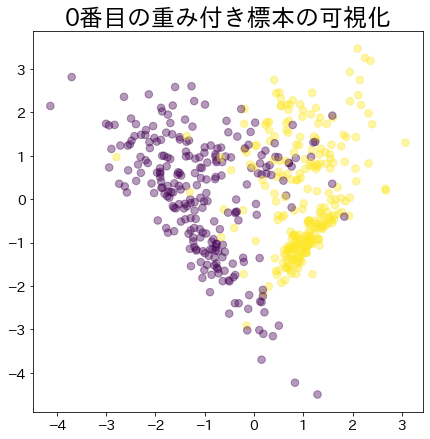
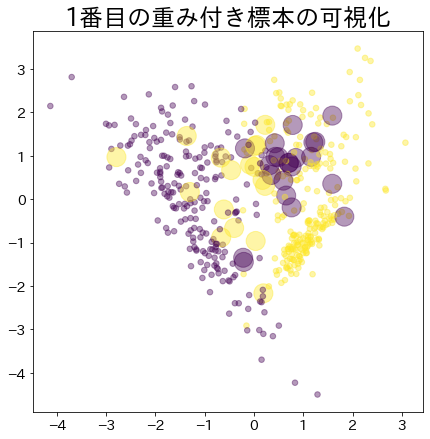
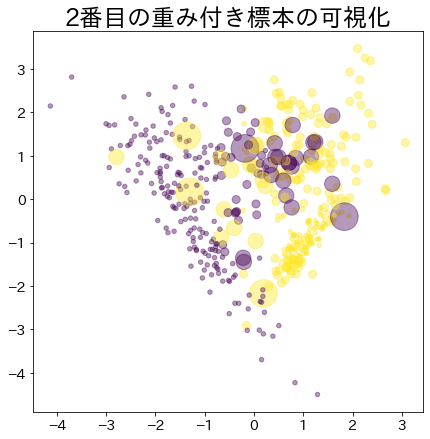
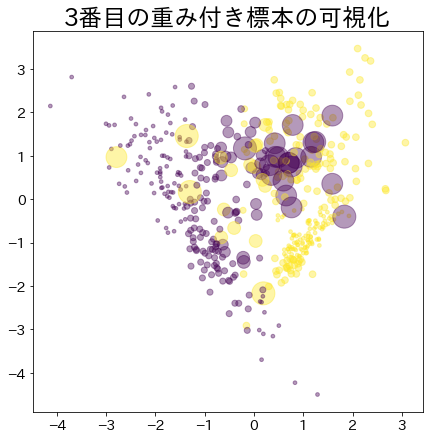
Weight after booting has progressed
#
The more weighted data is represented by a larger circle.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
| clf = AdaBoostClassifier(
n_estimators=4, random_state=0, algorithm="SAMME", base_estimator=DummyClassifier()
)
clf.fit(X_2, y_2)
for i, estimators_i in enumerate(clf.estimators_):
plt.figure(
figsize=(
7,
7,
)
)
plt.title(f"Visualization of the {i}-th weighted sample")
plt.scatter(
X_2[:, 0],
X_2[:, 1],
marker="o",
c=y_2,
alpha=0.4,
s=estimators_i.sample_weight * n_samples ** 1.65,
)
plt.show()
|