2.1.4
Polynomial Regression
Summary
- Polynomial regression expands features with powers so that a linear model can fit nonlinear relationships.
- The model remains a linear combination of coefficients, preserving closed-form solutions and interpretability.
- Higher degrees increase expressiveness but also invite overfitting, making regularization and cross-validation important.
- Standardizing features and tuning the degree plus penalty strength leads to stable predictions.
- Linear Regression — understanding this concept first will make learning smoother
Intuition #
This method should be interpreted through its assumptions, data conditions, and how parameter choices affect generalization.
Detailed Explanation #
Mathematical formulation #
Given \(\mathbf{x} = (x_1, \dots, x_m)\), we build a polynomial feature vector \(\phi(\mathbf{x})\) up to degree \(d\) and fit a linear regression on top of it. For \(m = 2\) and \(d = 2\),
$$ \phi(\mathbf{x}) = (1, x_1, x_2, x_1^2, x_1 x_2, x_2^2), $$and the model becomes
$$ y = \mathbf{w}^\top \phi(\mathbf{x}). $$As \(d\) grows, the number of terms increases rapidly, so in practice we start with degree 2 or 3 and pair it with regularization (e.g., Ridge) when necessary.
Experiments with Python #
Below we add third-degree polynomial features and fit a curve to data generated from a cubic function plus noise.
| |
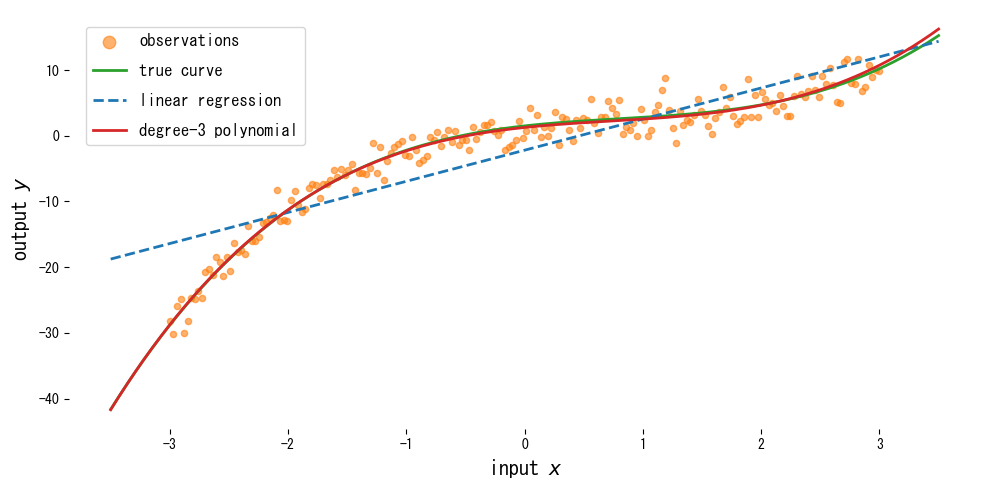
Reading the results #
- Plain linear regression misses the curvature, especially near the center, while the cubic polynomial follows the true curve closely.
- Increasing the degree improves training fit but can make extrapolation unstable.
- Combining polynomial features with a regularized regression (e.g., Ridge) via a pipeline helps curb overfitting.
References #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.