2.3.3
Decision Tree Parameters
- Decision trees expose several levers—depth, minimum samples per split/leaf, pruning, and class weights—that directly control their capacity and interpretability.
max_depthandmin_samples_leafcap how detailed the rules can become, whileccp_alpha(cost-complexity pruning) removes branches whose improvement does not justify their size.- Choosing the right criterion (
squared_error,absolute_error,friedman_mse, etc.) changes how aggressively the tree reacts to outliers. - Visual diagnostics of decision boundaries and tree structures help you communicate why a tuned set of hyperparameters works best.
- Decision Tree Classifier — understanding this concept first will make learning smoother
Intuition #
This method should be interpreted through its assumptions, data conditions, and how parameter choices affect generalization.
Detailed Explanation #
1. Overview #
A decision tree grows by repeatedly picking the split that yields the largest impurity decrease. Without constraints the tree keeps splitting until every leaf is pure, which often means overfitting. Hyperparameters therefore act as regularisers: depth limits keep the tree shallow, minimum sample counts avoid tiny leaves, and pruning collapses branches whose contribution is marginal.
2. Impurity gain and cost-complexity pruning #
For a parent node (P) split into children (L) and (R), the impurity decrease is
$$ \Delta I = I(P) - \frac{|L|}{|P|} I(L) - \frac{|R|}{|P|} I(R), $$where (I(\cdot)) can be the Gini index, entropy, MSE, or MAE depending on the task. A split is only kept if (\Delta I > 0).
Cost-complexity pruning scores an entire tree (T) with
$$ R_\alpha(T) = R(T) + \alpha |T|, $$where (R(T)) is the training loss (e.g., total squared error), (|T|) is the number of leaves, and (\alpha \ge 0) penalises large trees. Increasing (\alpha) encourages simpler structures.
3. Python experiments #
The snippet below trains several DecisionTreeRegressor models on a synthetic dataset and reports how different hyperparameters affect the training and validation (R^2). Adjusting max_depth, min_samples_leaf, or ccp_alpha shows how capacity and generalisation trade off.
| |
The following figures (shared with the Japanese page) illustrate how varying key knobs reshapes the prediction surface. Use them as a visual checklist when tuning your own tree:
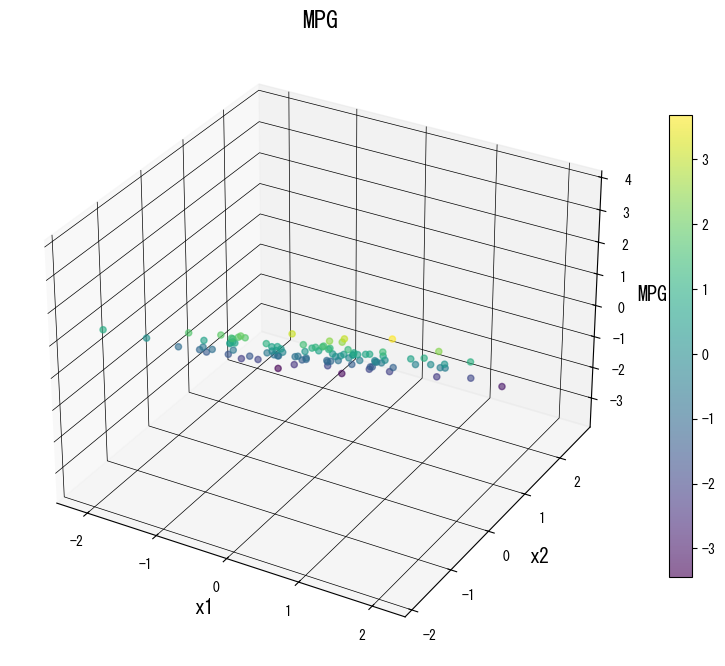
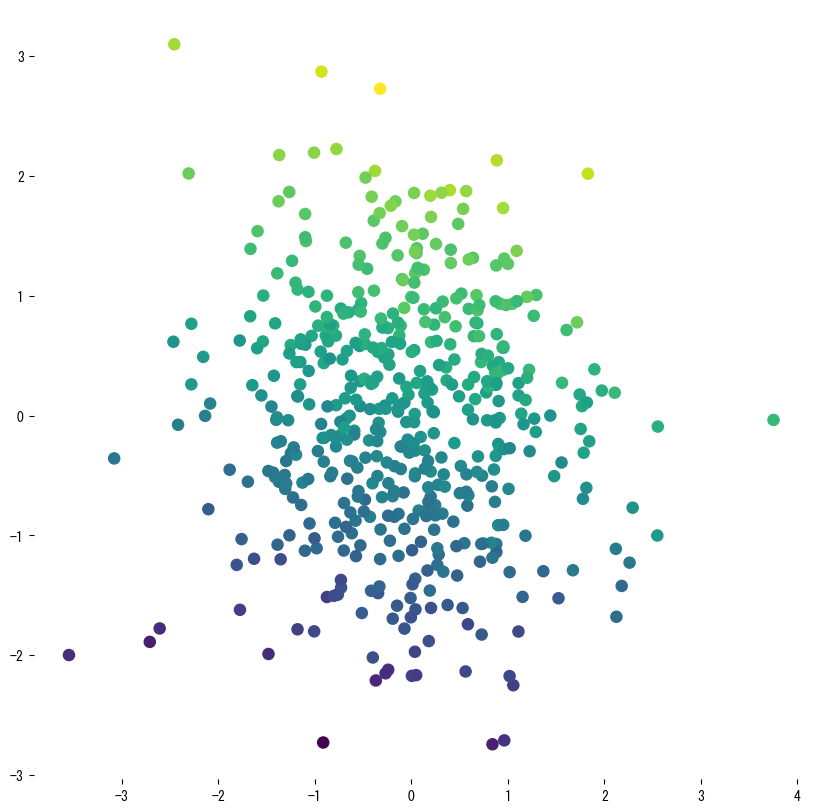
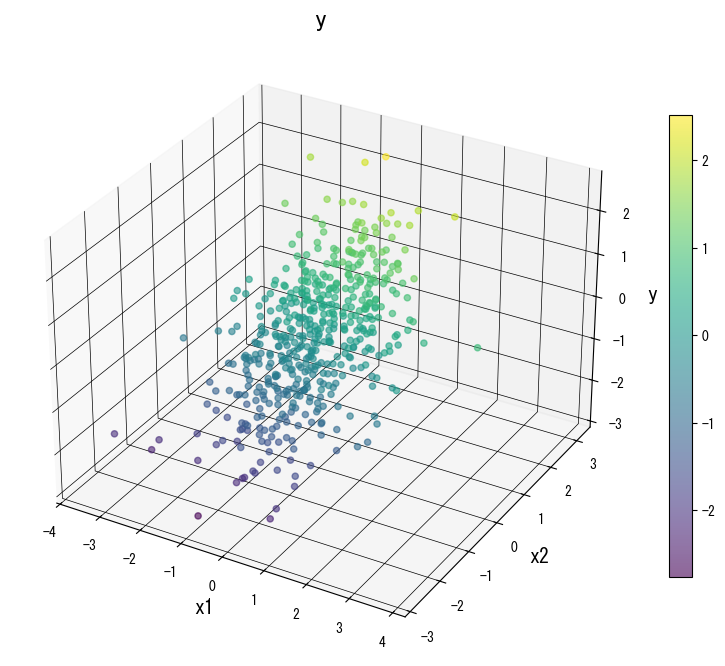
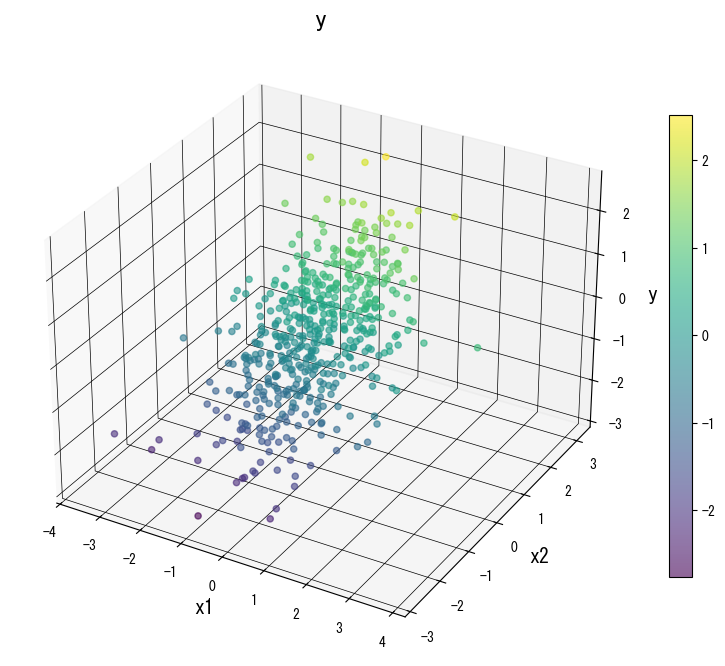
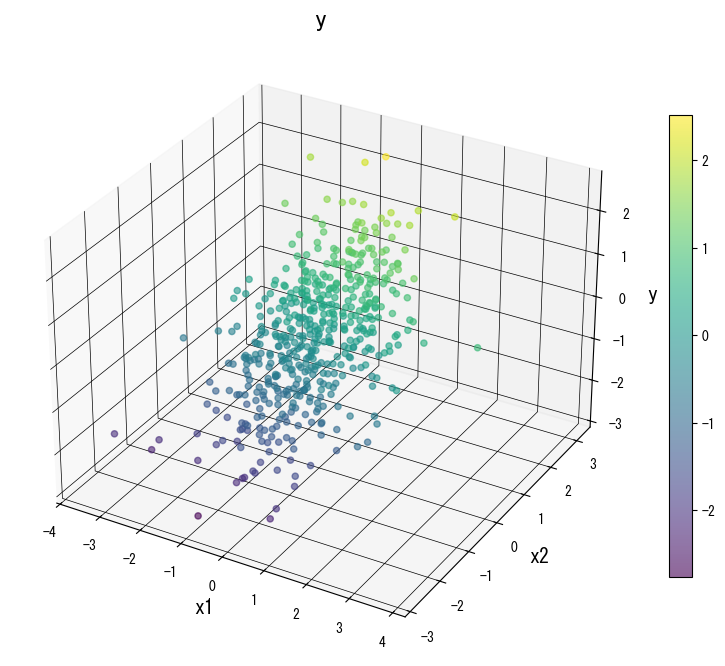
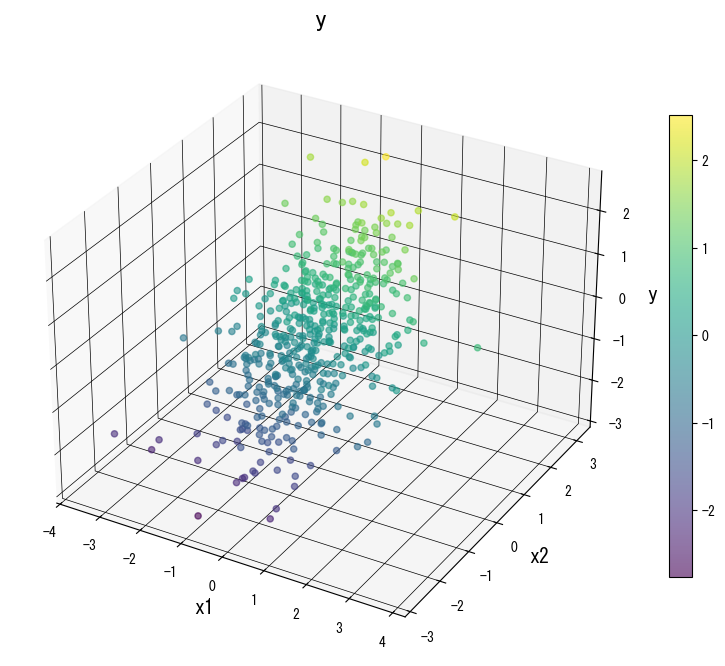
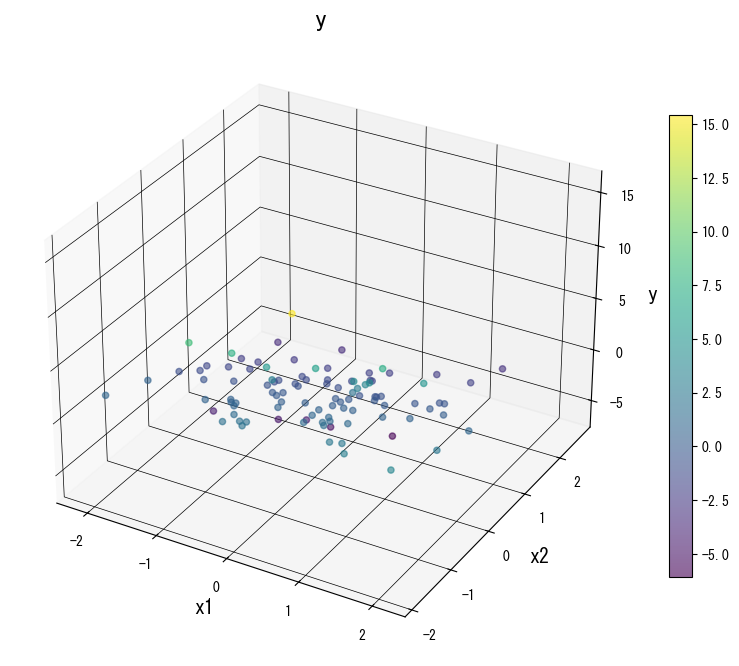
4. References #
- Breiman, L., Friedman, J. H., Olshen, R. A., & Stone, C. J. (1984). Classification and Regression Trees. Wadsworth.
- Breiman, L., & Friedman, J. H. (1991). Cost-Complexity Pruning. In Classification and Regression Trees. Chapman & Hall.
- scikit-learn developers. (2024). Decision Trees. https://scikit-learn.org/stable/modules/tree.html