2.9.1
ADTK básico
Resumen
- Organizar objetivo, supuestos y condiciones de uso del metodo.
- Revisar como reglas de actualizacion o criterios de division afectan el comportamiento.
- Usar ejemplos de implementacion para concretar decisiones de ajuste de parametros.
Intuicion #
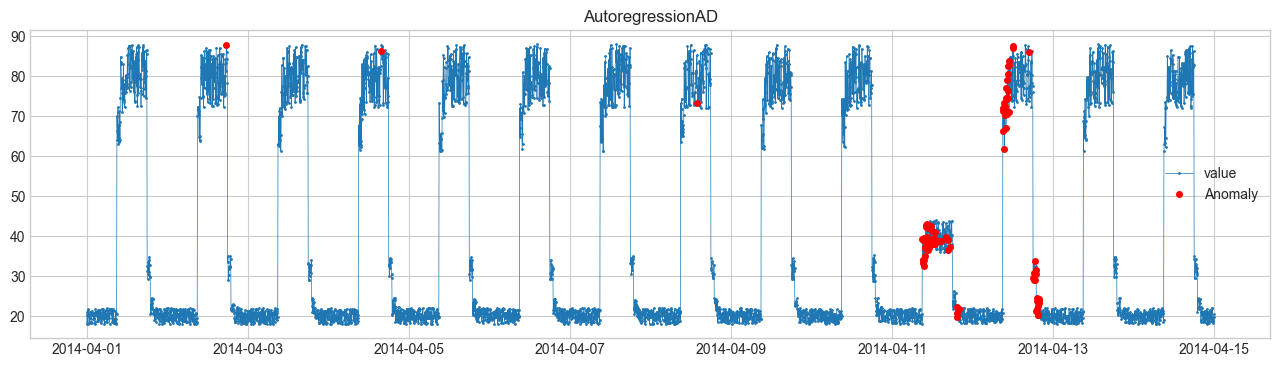
Vamos a realizar detección de anomalías utilizando Anomaly Detection Toolkit (ADTK). Los datos originales provienen de Numenta Anomaly Benchmark.
Explicacion Detallada #
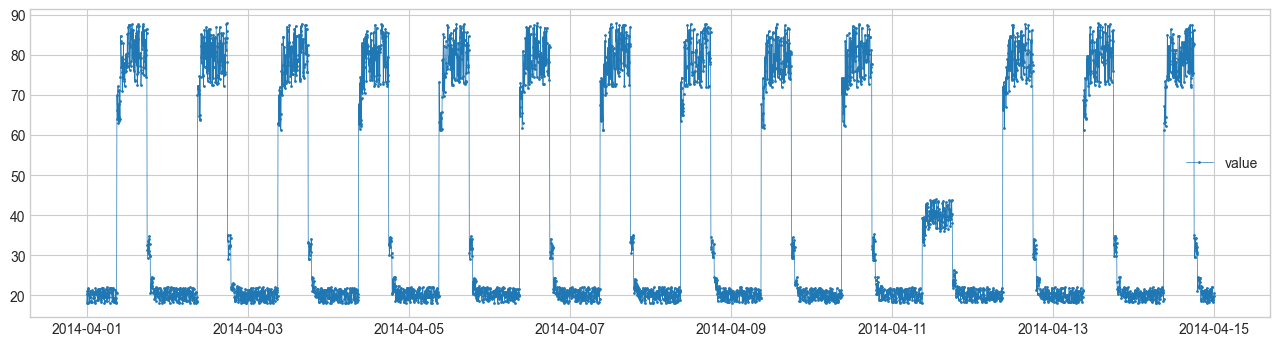
Vamos a realizar detección de anomalías utilizando Anomaly Detection Toolkit (ADTK). Los datos originales provienen de Numenta Anomaly Benchmark.
| |
timestamp
2014-04-01 00:00:00 18.090486
2014-04-01 00:05:00 20.359843
2014-04-01 00:10:00 21.105470
2014-04-01 00:15:00 21.151585
2014-04-01 00:20:00 18.137141
...
2014-04-14 23:35:00 18.269290
2014-04-14 23:40:00 19.087351
2014-04-14 23:45:00 19.594689
2014-04-14 23:50:00 19.767817
2014-04-14 23:55:00 20.479156
Freq: 5T, Name: value, Length: 4032, dtype: float64
s_train = pd.read_csv("./training.csv", index_col="timestamp", parse_dates=True, squeeze=True)
| |
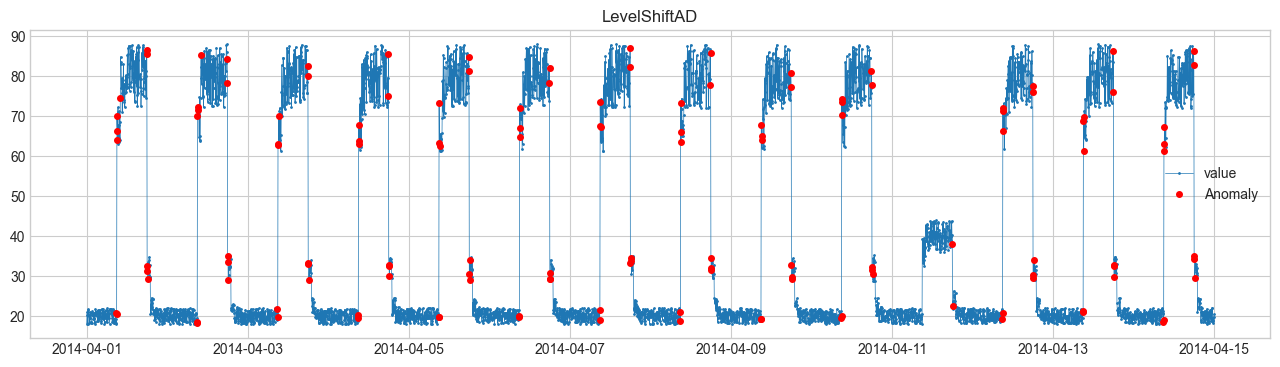
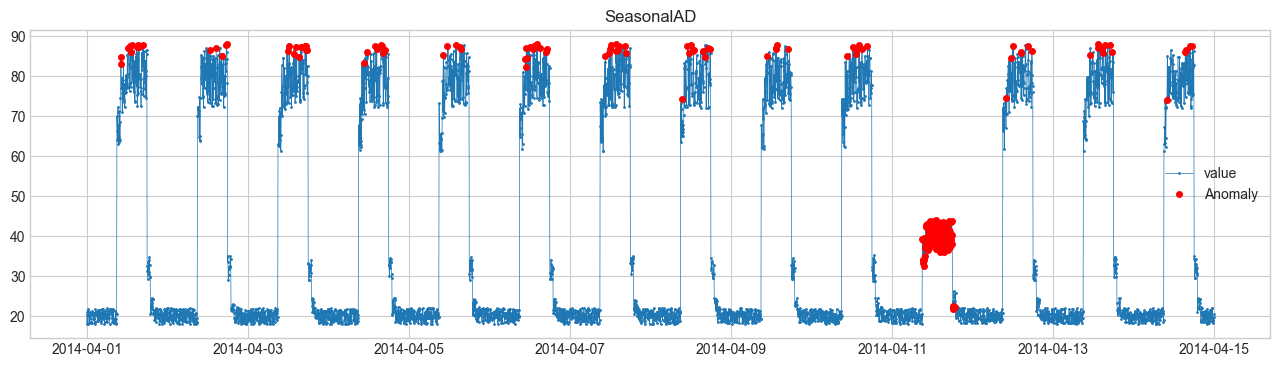
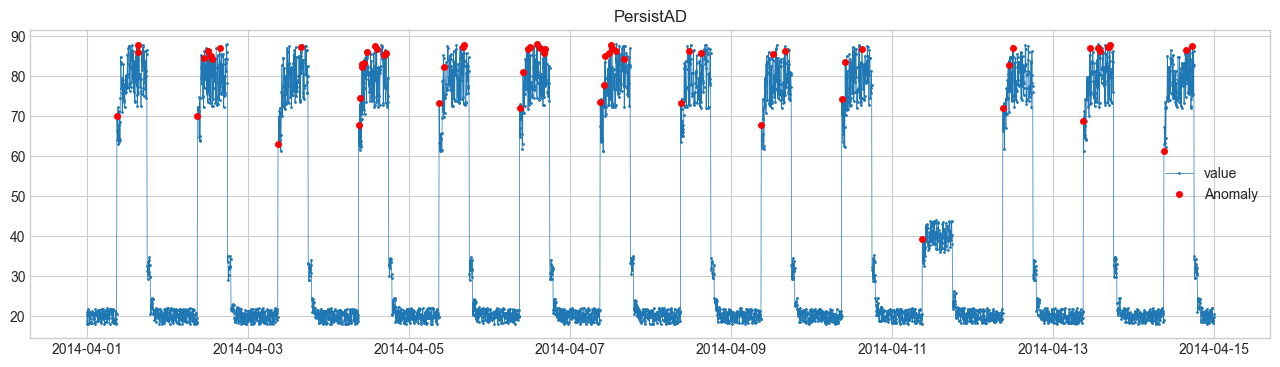
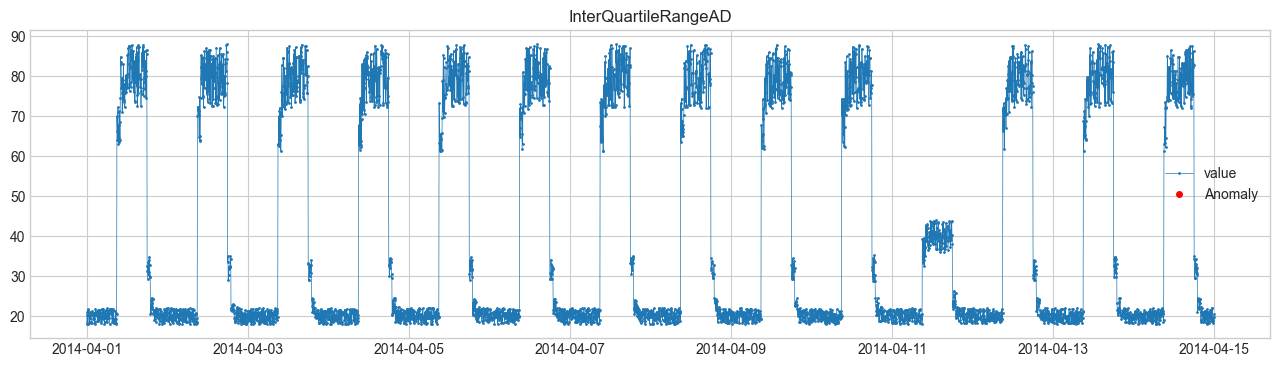
Comparación de métodos de detección de anomalías #
Realizaremos la detección de anomalías utilizando SeasonalAD. Para otros métodos, consulte Detector.
| |