2.2.7
k vecinos más cercanos (k-NN)
Resumen
- k-NN almacena los datos de entrenamiento y predice por mayoría entre los \(k\) vecinos más cercanos del punto a clasificar.
- Los principales hiperparámetros son el número de vecinos \(k\) y el esquema de ponderación de distancias, fáciles de explorar.
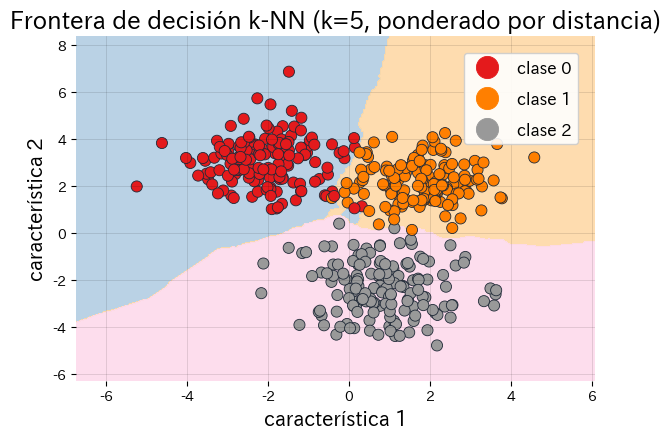
- Representa de forma natural fronteras de decisión no lineales, aunque las distancias pierden contraste en alta dimensión (“la maldición de la dimensionalidad”).
- Estandarizar las características o seleccionar las más relevantes estabiliza los cálculos de distancia.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
Para un punto de prueba \(\mathbf{x}\), sea \(\mathcal{N}_k(\mathbf{x})\) el conjunto de los \(k\) vecinos más cercanos. El voto para la clase \(c\) es
$$ v_c = \sum_{i \in \mathcal{N}_k(\mathbf{x})} w_i \,\mathbb{1}(y_i = c), $$donde los pesos \(w_i\) pueden ser uniformes o funciones de la distancia (inversa, gaussiana, etc.). La clase con mayor voto se predice como resultado.
Experimentos con Python #
El siguiente código evalúa distintos valores de \(k\) con un conjunto de validación y dibuja las regiones de decisión del mejor modelo.
| |
Referencias #
- Cover, T. M., & Hart, P. E. (1967). Nearest Neighbor Pattern Classification. IEEE Transactions on Information Theory, 13(1), 21–27.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.