2.2.4
Análisis discriminante lineal (LDA)
Resumen
- LDA busca direcciones que maximizan la razón entre la varianza entre clases y la varianza intraclase, por lo que sirve tanto para clasificar como para reducir la dimensionalidad.
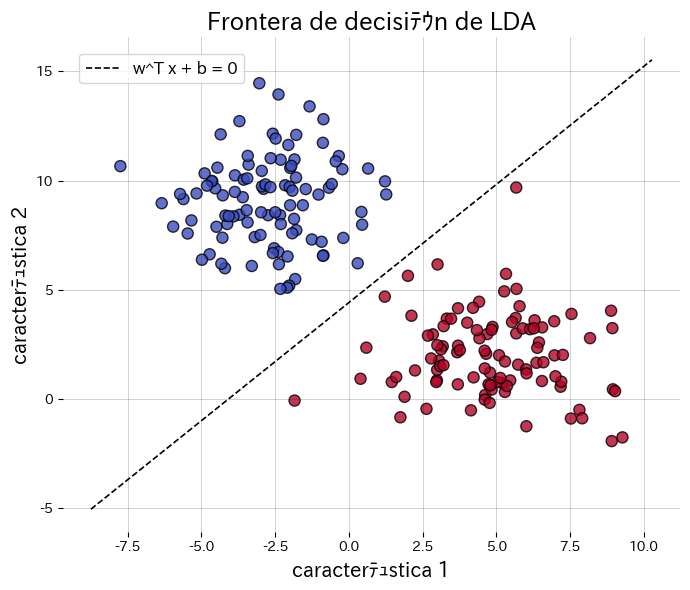
- La frontera de decisión es de la forma \(\mathbf{w}^\top \mathbf{x} + b = 0\); en 2D es una recta y en 3D un plano, lo que facilita su interpretación geométrica.
- Si cada clase sigue una distribución gaussiana con igual matriz de covarianza, LDA se aproxima al clasificador bayesiano óptimo.
- Con
LinearDiscriminantAnalysisde scikit-learn es sencillo visualizar la frontera de decisión y examinar las características proyectadas.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
Para dos clases, la dirección de proyección \(\mathbf{w}\) maximiza
$$ J(\mathbf{w}) = \frac{\mathbf{w}^\top \mathbf{S}_B \mathbf{w}}{\mathbf{w}^\top \mathbf{S}_W \mathbf{w}}, $$donde \(\mathbf{S}_B\) es la matriz de dispersión entre clases y \(\mathbf{S}_W\) la matriz de dispersión intraclase. En el caso multiclase se obtienen hasta \(K-1\) direcciones, útiles para reducir la dimensionalidad.
Experimentos con Python #
El código siguiente aplica LDA a un conjunto sintético de dos clases, dibuja la frontera de decisión y muestra la proyección a una dimensión. Con transform podemos obtener directamente los datos proyectados.
| |
Referencias #
- Fisher, R. A. (1936). The Use of Multiple Measurements in Taxonomic Problems. Annals of Eugenics, 7(2), 179"・88.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.