2.2.3
Perceptrón
Resumen
- El perceptrón converge en un número finito de actualizaciones si los datos son linealmente separables, siendo uno de los algoritmos de clasificación más antiguos.
- La predicción se basa en el signo de \(\mathbf{w}^\top \mathbf{x} + b\); cuando la señal es incorrecta, ese ejemplo actualiza los pesos.
- La regla de actualización “敗umar el ejemplo mal clasificado escalado por la tasa de aprendizaje”・ofrece una introducción intuitiva a los métodos basados en gradiente.
- Si los datos no son separables linealmente, conviene ampliar características o recurrir a kernel tricks.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
La predicción se calcula como
$$ \hat{y} = \operatorname{sign}(\mathbf{w}^\top \mathbf{x} + b). $$Si un ejemplo \((\mathbf{x}_i, y_i)\) queda mal clasificado, se actualiza mediante
$$ \mathbf{w} \leftarrow \mathbf{w} + \eta\, y_i\, \mathbf{x}_i,\qquad b \leftarrow b + \eta\, y_i. $$Cuando los datos son separables linealmente, este procedimiento converge.
Experimentos con Python #
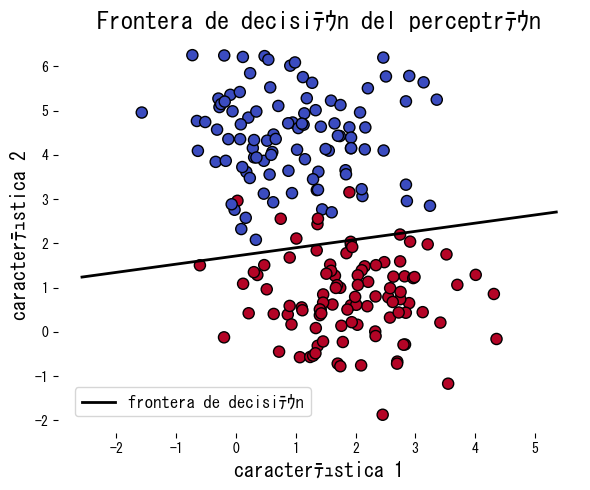
El siguiente ejemplo aplica el perceptrón a datos sintéticos, muestra el número de errores por época y dibuja la frontera obtenida.
| |
Referencias #
- Rosenblatt, F. (1958). The Perceptron: A Probabilistic Model for Information Storage and Organization in the Brain. Psychological Review, 65(6), 386"・08.
- Goodfellow, I., Bengio, Y., & Courville, A. (2016). Deep Learning. MIT Press.