2.2.5
Máquinas de vectores de soporte (SVM)
Resumen
- SVM aprende una frontera de decisión que maximiza el margen entre clases, priorizando la capacidad de generalización.
- El margen blando introduce variables de holgura; el parámetro \(C\) controla el equilibrio entre anchura del margen y errores permitidos.
- El truco del kernel reemplaza productos internos por funciones kernel, permitiendo fronteras no lineales sin expandir explícitamente las características.
- La estandarización de características y la búsqueda de hiperparámetros (\(C\), \(\gamma\), etc.) son claves para un buen rendimiento.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
Si los datos son separables linealmente, resolvemos
$$ \min_{\mathbf{w}, b} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1. $$En la práctica usamos la variante de margen blando con variables de holgura \(\xi_i \ge 0\):
$$ \min_{\mathbf{w}, b, \boldsymbol{\xi}} \ \frac{1}{2} \lVert \mathbf{w} \rVert_2^2 + C \sum_{i=1}^{n} \xi_i \quad \text{s.t.} \quad y_i(\mathbf{w}^\top \mathbf{x}_i + b) \ge 1 - \xi_i. $$Sustituir los productos internos \(\mathbf{x}_i^\top \mathbf{x}_j\) por un kernel \(K(\mathbf{x}_i, \mathbf{x}_j)\) permite modelar fronteras no lineales.
Experimentos con Python #
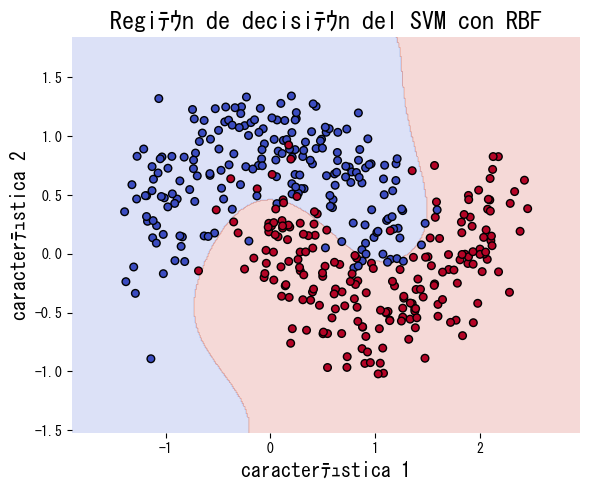
El código siguiente entrena SVM con kernel lineal y con kernel RBF sobre datos generados por make_moons, que no son separables linealmente. El kernel RBF captura la frontera curva con mayor precisión.
| |
Referencias #
- Vapnik, V. (1998). Statistical Learning Theory. Wiley.
- Smola, A. J., & Schölkopf, B. (2004). A Tutorial on Support Vector Regression. Statistics and Computing, 14(3), 199"・22.