2.5.5
Modelo de Mezclas Gaussianas (GMM)
Resumen
- Un GMM describe los datos como la suma ponderada de normales multivariadas.
- Devuelve una matriz de responsabilidades que cuantifica cuánta probabilidad aporta cada componente a cada muestra.
- Los parámetros se estiman con el algoritmo EM; la estructura de covarianzas puede ser
full,tied,diagospherical. - Para elegir el modelo se combinan BIC/AIC con múltiples inicializaciones aleatorias que evitan soluciones inestables.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación #
La densidad de \(\mathbf{x}\) es
$$ p(\mathbf{x}) = \sum_{k=1}^{K} \pi_k \, \mathcal{N}(\mathbf{x} \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k), $$con pesos \(\pi_k\) (no negativos y cuya suma es 1). EM alterna:
- E-step: cálculo de responsabilidades \(\gamma_{ik}\). $$ \gamma_{ik} = \frac{\pi_k \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_k, \boldsymbol{\Sigma}_k)} {\sum_{j=1}^K \pi_j \, \mathcal{N}(\mathbf{x}_i \mid \boldsymbol{\mu}_j, \boldsymbol{\Sigma}_j)}. $$
- M-step: reestimación de \(\pi_k, \boldsymbol{\mu}_k, \boldsymbol{\Sigma}k\) ponderada por \(\gamma{ik}\).
La log-verosimilitud aumenta de forma monótona hasta un máximo local.
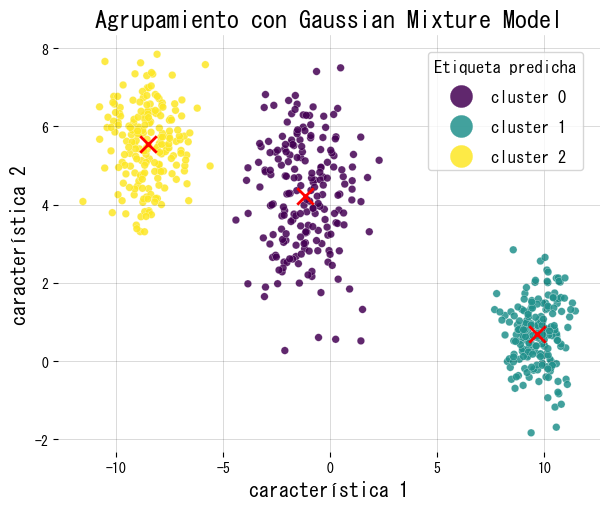
Ejemplo en Python #
Ajustamos un GMM a datos sintéticos en 2D, representamos las etiquetas duras y mostramos pesos y responsabilidades.
| |
Referencias #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Dempster, A. P., Laird, N. M., & Rubin, D. B. (1977). Maximum Likelihood from Incomplete Data via the EM Algorithm. Journal of the Royal Statistical Society, Series B.
- scikit-learn developers. (2024). Gaussian Mixture Models. https://scikit-learn.org/stable/modules/mixture.html