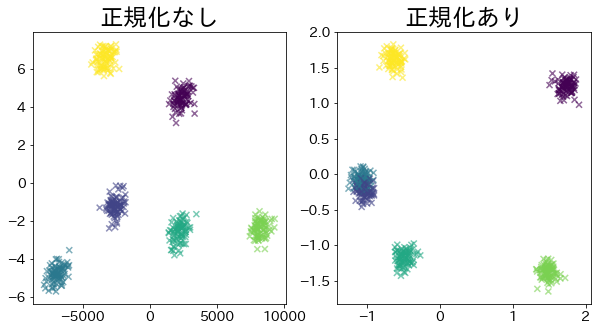
PCA rota el sistema de coordenadas hacia direcciones informativas. Conservando pocos ejes principales se reduce dimension sin perder la estructura dominante.
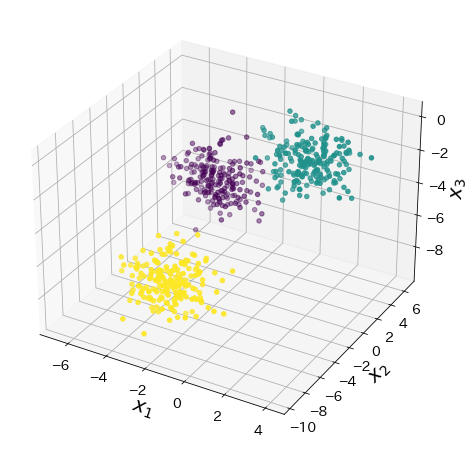
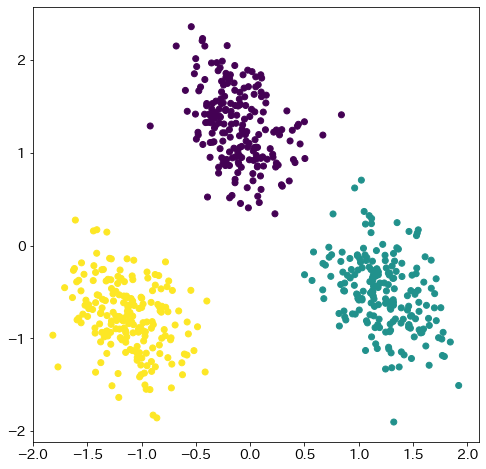
# Datos experimentalesX,y=make_blobs(n_samples=200,n_features=3,random_state=11711,centers=3,cluster_std=2.0)X[:,1]=X[:,1]*1000X[:,2]=X[:,2]*0.01X_ss=StandardScaler().fit_transform(X)# Graficar los datos originalesfig=plt.figure(figsize=(8,8))ax=fig.add_subplot(projection="3d")ax.scatter(X[:,0],X[:,1],X[:,2],marker="o",c=y)ax.set_xlabel("$x_1$")ax.set_ylabel("$x_2$")ax.set_zlabel("$x_3$")plt.title("Datos experimentales")plt.show()# PCA sin normalizaciónpca=PCA(n_components=2).fit(X)X_pca=pca.transform(X)# PCA con normalizaciónpca_ss=PCA(n_components=2).fit(X_ss)X_pca_ss=pca_ss.transform(X_ss)fig=plt.figure(figsize=(10,5))plt.subplot(121)plt.title("Sin normalización")plt.scatter(X_pca[:,0],X_pca[:,1],c=y,marker="x",alpha=0.6)plt.subplot(122)plt.title("Con normalización")plt.scatter(X_pca_ss[:,0],X_pca_ss[:,1],c=y,marker="x",alpha=0.6)
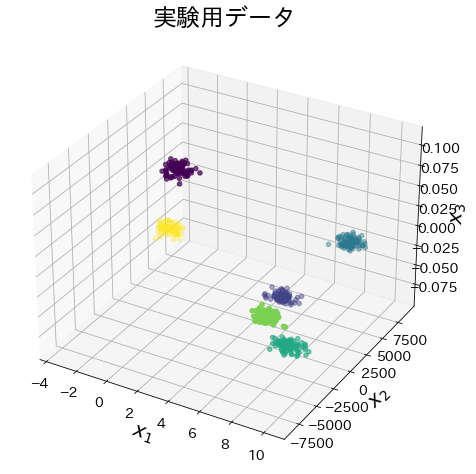
Número de clústeres: 6, sin superposición entre clústeres
#
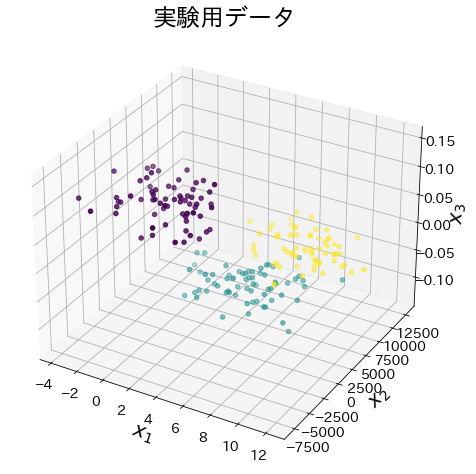
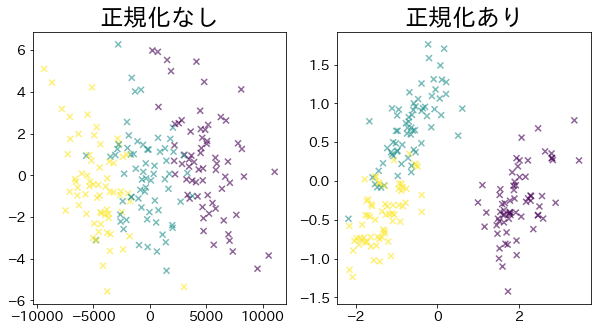
# Datos experimentalesX,y=make_blobs(n_samples=500,n_features=3,random_state=11711,centers=6,cluster_std=0.4)X[:,1]=X[:,1]*1000X[:,2]=X[:,2]*0.01X_ss=StandardScaler().fit_transform(X)# Graficar los datos originalesfig=plt.figure(figsize=(8,8))ax=fig.add_subplot(projection="3d")ax.scatter(X[:,0],X[:,1],X[:,2],marker="o",c=y)ax.set_xlabel("$x_1$")ax.set_ylabel("$x_2$")ax.set_zlabel("$x_3$")plt.title("Datos experimentales")plt.show()# PCA sin normalizaciónpca=PCA(n_components=2).fit(X)X_pca=pca.transform(X)# PCA con normalizaciónpca_ss=PCA(n_components=2).fit(X_ss)X_pca_ss=pca_ss.transform(X_ss)fig=plt.figure(figsize=(10,5))plt.subplot(121)plt.title("Sin normalización")plt.scatter(X_pca[:,0],X_pca[:,1],c=y,marker="x",alpha=0.6)plt.subplot(122)plt.title("Con normalización")plt.scatter(X_pca_ss[:,0],X_pca_ss[:,1],c=y,marker="x",alpha=0.6)