En regresión, AdaBoost dirige cada iteración hacia los casos peor ajustados. Esa reasignación progresiva de foco permite capturar estructuras de error no lineales que un único modelo base no corrige bien.
# NOTA: Modelo creado para observar sample_weight en AdaboostclassDummyRegressor:def__init__(self):self.model=DecisionTreeRegressor(max_depth=5)self.error_vector=Noneself.X_for_plot=Noneself.y_for_plot=Nonedeffit(self,X,y):self.model.fit(X,y)y_pred=self.model.predict(X)# El peso se calcula en función del error de regresión# Referencia: https://github.com/scikit-learn/scikit-learn/blob/main/sklearn/ensemble/_weight_boosting.py#L1130self.error_vector=np.abs(y_pred-y)self.X_for_plot=X.copy()self.y_for_plot=y.copy()returnself.modeldefpredict(self,X,check_input=True):returnself.model.predict(X)defget_params(self,deep=False):return{}defset_params(self,deep=False):return{}
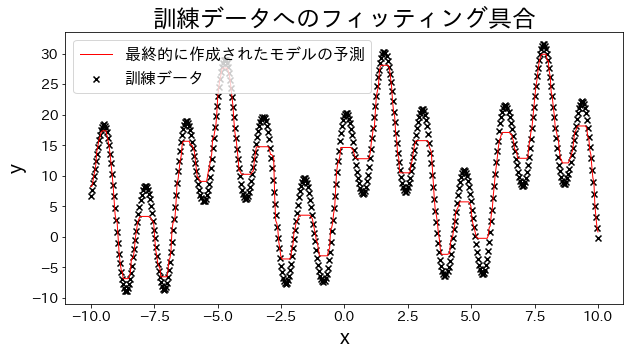
Ajustar un modelo de regresión a los datos de entrenamiento
#
# Datos de entrenamientoX=np.linspace(-10,10,500)[:,np.newaxis]y=(np.sin(X).ravel()+np.cos(4*X).ravel())*10+10+np.linspace(-2,2,500)# Crear el modelo de regresiónreg=AdaBoostRegressor(DummyRegressor(),n_estimators=100,random_state=100,loss="linear",learning_rate=0.8,)reg.fit(X,y)y_pred=reg.predict(X)# Evaluar el ajuste del modelo a los datos de entrenamientoplt.figure(figsize=(10,5))plt.scatter(X,y,c="k",marker="x",label="Datos de entrenamiento")plt.plot(X,y_pred,c="r",label="Predicción del modelo final",linewidth=1)plt.xlabel("x")plt.ylabel("y")plt.title("Evaluación del ajuste a los datos de entrenamiento")plt.legend()plt.show()
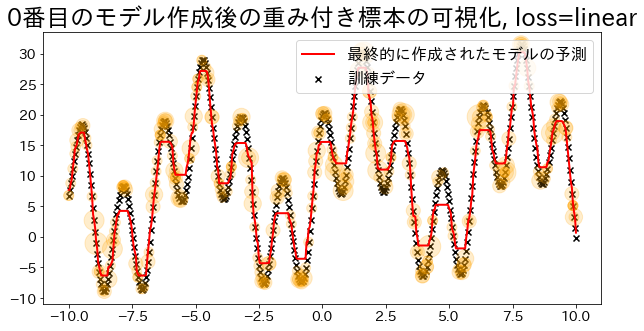
Visualización de los pesos de las muestras (cuando loss='linear')
#
En Adaboost, los pesos de las muestras se determinan en función del error de regresión. Visualizaremos la magnitud de los pesos cuando el parámetro loss está configurado como 'linear'. Observaremos cómo las muestras con mayor peso tienen una probabilidad más alta de ser seleccionadas durante el entrenamiento.
loss{‘linear’, ‘square’, ‘exponential’}, default=’linear’
The loss function to use when updating the weights after each boosting iteration.
defvisualize_weight(reg,X,y,y_pred):"""Función para visualizar los valores equivalentes a los pesos de las muestras (frecuencia de muestreo)
Parameters
----------
reg : sklearn.ensemble._weight_boosting
Modelo de boosting
X : numpy.ndarray
Datos de entrenamiento
y : numpy.ndarray
Datos objetivo
y_pred:
Predicciones del modelo
"""assertreg.estimators_isnotNone,"len(reg.estimators_) > 0"fori,estimators_iinenumerate(reg.estimators_):ifi%100==0:# Contar la cantidad de veces que aparece cada dato en la creación del modelo número iweight_dict={xi:0forxiinX.ravel()}forxiinestimators_i.X_for_plot.ravel():weight_dict[xi]+=1# Graficar la frecuencia de aparición con círculos naranjas (más frecuencia, círculos más grandes)weight_x_sorted=sorted(weight_dict.items(),key=lambdax:x[0])weight_vec=np.array([s*100forxi,sinweight_x_sorted])# Graficarplt.figure(figsize=(10,5))plt.title(f"Visualización de las muestras ponderadas tras el modelo número {i}, loss={reg.loss}")plt.scatter(X,y,c="k",marker="x",label="Datos de entrenamiento")plt.scatter(estimators_i.X_for_plot,estimators_i.y_for_plot,marker="o",alpha=0.2,c="orange",s=weight_vec,)plt.plot(X,y_pred,c="r",label="Predicción del modelo final",linewidth=2)plt.legend(loc="upper right")plt.show()## Crear el modelo de regresión con loss="linear"reg=AdaBoostRegressor(DummyRegressor(),n_estimators=101,random_state=100,loss="linear",learning_rate=1,)reg.fit(X,y)y_pred=reg.predict(X)visualize_weight(reg,X,y,y_pred)
1
2
3
4
5
6
7
8
9
10
11
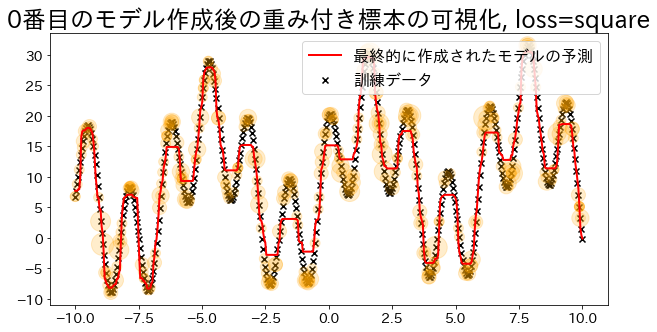
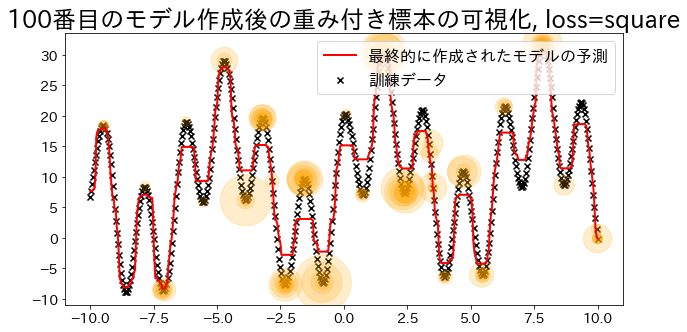
## Crear un modelo de regresión con `loss="square"`reg=AdaBoostRegressor(DummyRegressor(),n_estimators=101,random_state=100,loss="square",learning_rate=1,)reg.fit(X,y)y_pred=reg.predict(X)visualize_weight(reg,X,y,y_pred)