Bosque Aleatorio es un algoritmo de aprendizaje en conjunto que mejora la capacidad de generalización y la precisión de las predicciones al combinar árboles de decisión creados utilizando características seleccionadas al azar.
En esta página, ejecutaremos un Bosque Aleatorio y exploraremos el rendimiento y los detalles de los árboles de decisión individuales dentro del modelo.
fromsklearn.datasetsimportmake_classificationfromsklearn.ensembleimportRandomForestClassifierfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportroc_auc_scoren_features=20X,y=make_classification(n_samples=2500,n_features=n_features,n_informative=10,n_classes=2,n_redundant=0,n_clusters_per_class=4,random_state=777,)X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.33,random_state=777)model=RandomForestClassifier(n_estimators=50,max_depth=3,random_state=777,bootstrap=True,oob_score=True)model.fit(X_train,y_train)y_pred=model.predict(X_test)rf_score=roc_auc_score(y_test,y_pred)print(f"ROC-AUC en los datos de prueba = {rf_score}")
ROC-AUC en los datos de prueba = 0.814573097628059
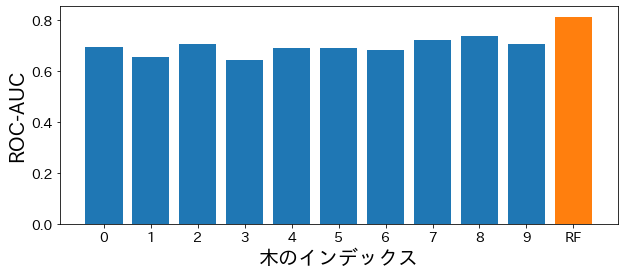
Verificar el rendimiento de cada árbol incluido en el Bosque Aleatorio
#
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
importjapanize_matplotlibestimator_scores=[]foriinrange(10):estimator=model.estimators_[i]estimator_pred=estimator.predict(X_test)estimator_scores.append(roc_auc_score(y_test,estimator_pred))plt.figure(figsize=(10,4))bar_index=[iforiinrange(len(estimator_scores))]plt.bar(bar_index,estimator_scores)plt.bar([10],rf_score)plt.xticks(bar_index+[10],bar_index+["RF"])plt.xlabel("Índice del Árbol")plt.ylabel("ROC-AUC")plt.show()
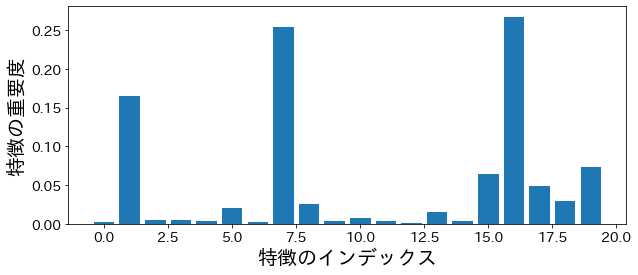
El siguiente gráfico muestra la importancia de las características calculada en función de la reducción de impureza en el modelo de Bosque Aleatorio. Esto nos permite identificar cuáles son las características más relevantes para las predicciones.
1
2
3
4
5
6
plt.figure(figsize=(10,4))feature_index=[iforiinrange(n_features)]plt.bar(feature_index,model.feature_importances_)plt.xlabel("Índice de la Característica")plt.ylabel("Importancia de la Característica")plt.show()
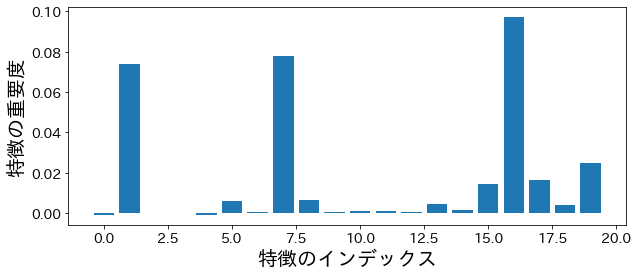
fromsklearn.inspectionimportpermutation_importancep_imp=permutation_importance(model,X_train,y_train,n_repeats=10,random_state=77).importances_meanplt.figure(figsize=(10,4))plt.bar(feature_index,p_imp)plt.xlabel("Índice de la Característica")plt.ylabel("Importancia de la Característica")plt.show()
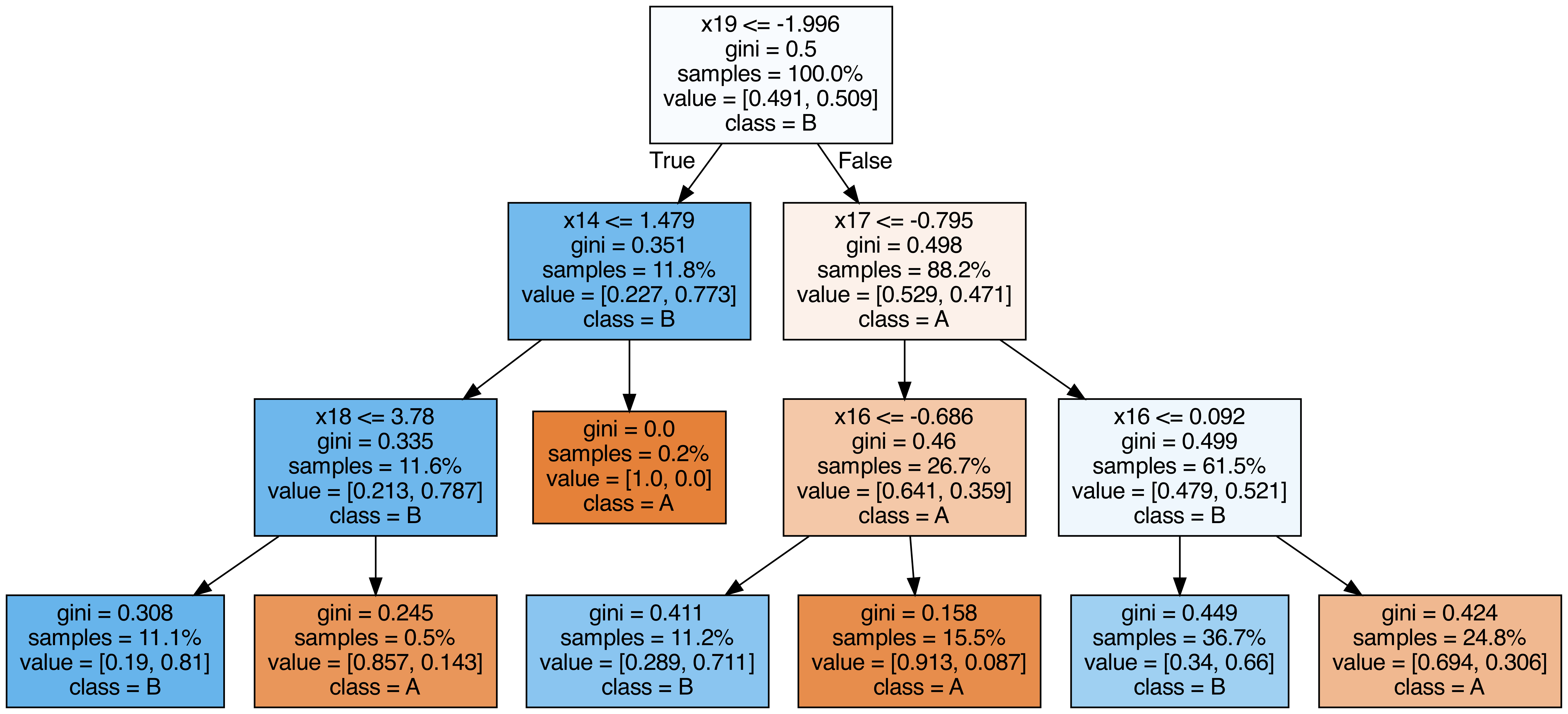
Exportar cada árbol incluido en el Bosque Aleatorio
#
La validación mediante OOB permite verificar que los resultados obtenidos son consistentes con los obtenidos en los datos de prueba. Esto asegura que el modelo generaliza bien sin sobreajustarse.
En esta sección, compararemos la precisión obtenida con OOB y la precisión en los datos de prueba al variar los parámetros como la semilla aleatoria y la profundidad de los árboles.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
fromsklearn.metricsimportaccuracy_scoreforiinrange(10):model_i=RandomForestClassifier(n_estimators=50,max_depth=3+i%2,random_state=i,bootstrap=True,oob_score=True,)model_i.fit(X_train,y_train)y_pred=model_i.predict(X_test)oob_score=model_i.oob_score_test_score=accuracy_score(y_test,y_pred)print(f"Validación OOB={oob_score} Validación en Datos de Prueba={test_score}")