Stacking se refiere a un modelo que repite el proceso de “crear múltiples modelos de predicción y usar sus salidas como entrada para otro modelo de predicción”. En esta página, implementaremos el stacking y analizaremos qué modelos de la primera capa resultaron más efectivos.
En esta sección, se generarán datos con 20 características para realizar los experimentos.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
# Crear datos con 20 característicasn_features=20X,y=make_classification(n_samples=2500,n_features=n_features,n_informative=10,n_classes=2,n_redundant=0,n_clusters_per_class=4,random_state=777,)X_train,X_test,y_train,y_test=train_test_split(X,y,test_size=0.33,random_state=777)
Representación Gráfica de los Datos Según Varias Características
#
El objetivo de esta sección es visualizar los datos generados utilizando múltiples características para verificar que no pueden ser clasificados fácilmente mediante reglas simples.
En esta sección, implementaremos el método de Stacking utilizando únicamente DecisionTreeClassifier. Esto nos permitirá observar que la precisión no mejora significativamente cuando se utiliza un solo tipo de modelo.
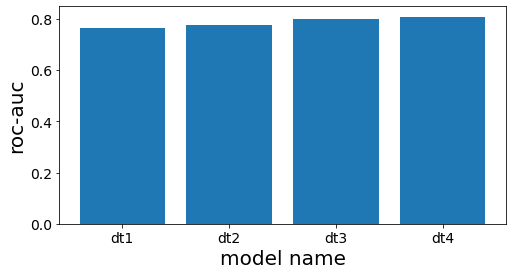
Comparación de ROC-AUC: Stacking vs. Bosque Aleatorio
#
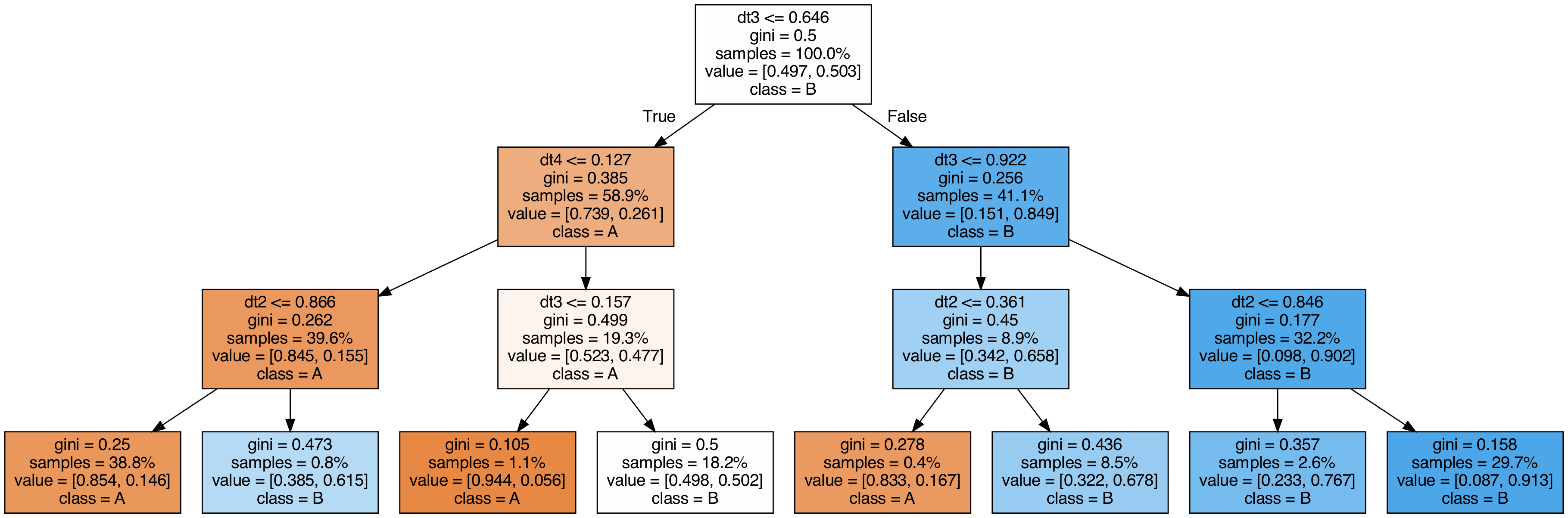
El siguiente código implementa un modelo de Stacking compuesto únicamente por DecisionTreeClassifier con diferentes profundidades como modelos base, seguido de otro DecisionTreeClassifier como modelo final. Luego, compara su rendimiento (ROC-AUC) con el de un modelo de Bosque Aleatorio previamente entrenado.
fromsklearn.treeimportDecisionTreeClassifierfromsklearn.ensembleimportStackingClassifierfromsklearn.metricsimportroc_auc_score# Modelos base para la primera capa del Stackingestimators=[("dt1",DecisionTreeClassifier(max_depth=3,random_state=777)),("dt2",DecisionTreeClassifier(max_depth=4,random_state=777)),("dt3",DecisionTreeClassifier(max_depth=5,random_state=777)),("dt4",DecisionTreeClassifier(max_depth=6,random_state=777)),]# Número de modelos base en el Stackingn_estimators=len(estimators)# Modelo final del Stackingfinal_estimator=DecisionTreeClassifier(max_depth=3,random_state=777)# Crear y entrenar el modelo de Stackingclf=StackingClassifier(estimators=estimators,final_estimator=final_estimator)clf.fit(X_train,y_train)# Evaluación en los datos de pruebay_pred=clf.predict(X_test)clf_score=roc_auc_score(y_test,y_pred)print("ROC-AUC")print(f"Stacking con Árboles de Decisión = {clf_score:.4f}, Bosque Aleatorio = {rf_score:.4f}")
ROC-AUC
Stacking con Árboles de Decisión=0.7359716965608031, Bosque Aleatorio=0.855797033310609
Visualización de los Árboles Utilizados en el Stacking
#
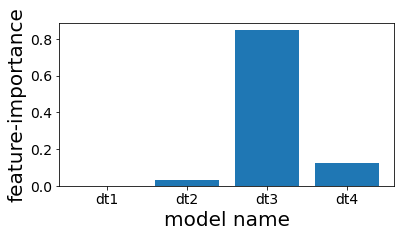
Importancia de las Características en los Árboles Utilizados en el Stacking
#
En esta sección, evaluaremos la importancia de las características en los árboles de decisión utilizados dentro del modelo de Stacking. Esto nos permitirá observar si algún árbol domina el proceso de predicción.