2.1.6
Regresión lineal bayesiana
Resumen
- La regresión lineal bayesiana trata los coeficientes como variables aleatorias y estima simultáneamente las predicciones y su incertidumbre.
- La distribución posterior se obtiene de forma analítica a partir de la distribución previa y la verosimilitud, lo que la hace robusta con pocos datos o mucho ruido.
- La distribución predictiva es gaussiana, de modo que su media y varianza se pueden visualizar para apoyar la toma de decisiones.
BayesianRidgeen scikit-learn ajusta automáticamente la varianza del ruido y facilita el uso práctico del método.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
Suponemos una distribución previa gaussiana multivariante de media 0 y varianza \(\tau^{-1}\) para el vector de coeficientes \(\boldsymbol\beta\), y ruido gaussiano \(\epsilon_i \sim \mathcal{N}(0, \alpha^{-1})\) en las observaciones. La posterior resulta ser
$$ p(\boldsymbol\beta \mid \mathbf{X}, \mathbf{y}) = \mathcal{N}(\boldsymbol\beta \mid \boldsymbol\mu, \mathbf{\Sigma}) $$con
$$ \mathbf{\Sigma} = (\alpha \mathbf{X}^\top \mathbf{X} + \tau \mathbf{I})^{-1}, \qquad \boldsymbol\mu = \alpha \mathbf{\Sigma} \mathbf{X}^\top \mathbf{y}. $$La distribución predictiva para una nueva entrada \(\mathbf{x}*\) también es gaussiana, \(\mathcal{N}(\hat{y}, \sigma_^2)\). BayesianRidge estima \(\alpha\) y \(\tau\) a partir de los datos, evitando un ajuste manual.
Experimentos con Python #
El ejemplo siguiente compara mínimos cuadrados ordinarios con la regresión lineal bayesiana en presencia de valores atípicos.
| |
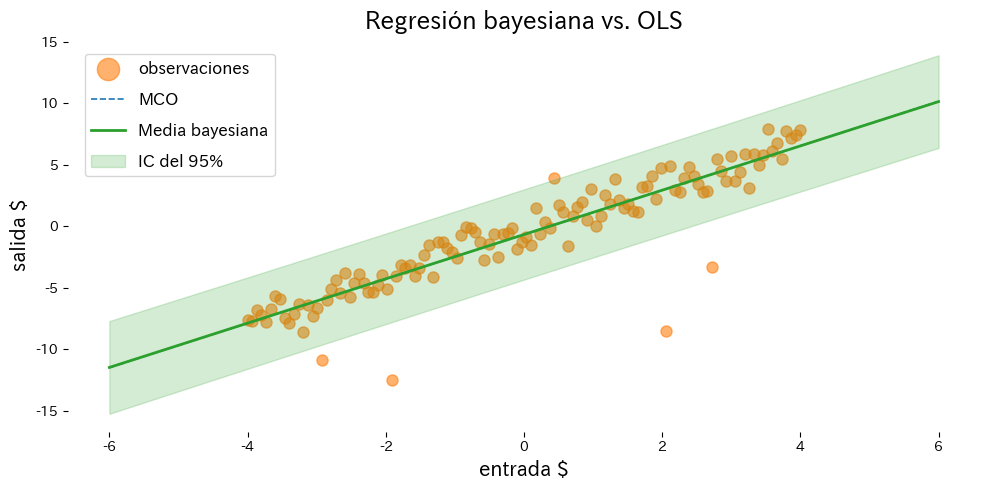
Interpretación de los resultados #
- OLS se ve arrastrado por los outliers, mientras que la regresión bayesiana mantiene más estable la predicción media.
return_std=Truedevuelve la desviación estándar predictiva y permite trazar intervalos creíbles con facilidad.- La varianza posterior revela qué coeficientes conservan mayor incertidumbre.
Referencias #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Murphy, K. P. (2012). Machine Learning: A Probabilistic Perspective. MIT Press.