2.1.4
Regresión polinómica
Resumen
- La regresión polinómica amplía las características con potencias para que un modelo lineal pueda ajustar relaciones no lineales.
- El modelo sigue siendo una combinación lineal de coeficientes, por lo que mantiene soluciones cerradas e interpretabilidad.
- A mayor grado mayor expresividad, pero también riesgo de sobreajuste; por ello la regularización y la validación cruzada son esenciales.
- Estandarizar las características y ajustar el grado junto con la penalización produce predicciones estables.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
Para \(\mathbf{x} = (x_1, \dots, x_m)\) generamos un vector de características polinómicas \(\phi(\mathbf{x})\) hasta el grado \(d\). Por ejemplo, si \(m = 2\) y \(d = 2\),
$$ \phi(\mathbf{x}) = (1, x_1, x_2, x_1^2, x_1 x_2, x_2^2), $$y el modelo queda
$$ y = \mathbf{w}^\top \phi(\mathbf{x}). $$Como el número de términos crece rápidamente con el grado, en la práctica se comienza con grados bajos (2 o 3) y se combina con regularización (p. ej., Ridge) cuando hace falta.
Experimentos con Python #
Añadimos características de grado tres y ajustamos una curva a datos generados a partir de una función cúbica con ruido.
| |
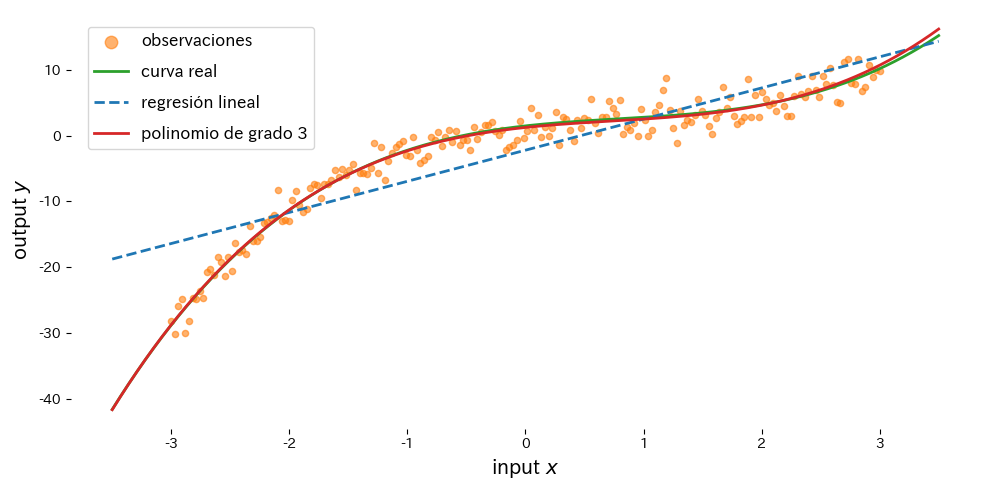
Interpretación de los resultados #
- La regresión lineal simple falla en reproducir la curvatura, especialmente cerca del centro, mientras que el modelo cúbico sigue la curva verdadera.
- Subir el grado mejora el ajuste en entrenamiento pero puede volver inestables las extrapolaciones.
- Combinar características polinómicas con una regresión regularizada (p. ej., Ridge) en una tubería ayuda a controlar el sobreajuste.
Referencias #
- Bishop, C. M. (2006). Pattern Recognition and Machine Learning. Springer.
- Hastie, T., Tibshirani, R., & Friedman, J. (2009). The Elements of Statistical Learning. Springer.