2.1.8
Regresión por componentes principales (PCR)
Resumen
- PCR aplica PCA para comprimir las características antes de ajustar la regresión lineal, reduciendo la inestabilidad causada por la multicolinealidad.
- Los componentes principales priorizan las direcciones con mayor varianza, filtrando el ruido y preservando la estructura informativa.
- Elegir cuántos componentes conservar permite equilibrar el riesgo de sobreajuste y el coste computacional.
- Un buen preprocesamiento —estandarización y tratamiento de valores perdidos— sienta las bases para un modelo preciso e interpretable.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
Aplicamos PCA a la matriz de diseño estandarizada \(\mathbf{X}\) y conservamos los \(k\) autovectores principales. Con las puntuaciones \(\mathbf{Z} = \mathbf{X} \mathbf{W}_k\), el modelo de regresión
$$ y = \boldsymbol{\gamma}^\top \mathbf{Z} + b $$se ajusta a los datos. Los coeficientes en el espacio original se recuperan mediante \(\boldsymbol{\beta} = \mathbf{W}_k \boldsymbol{\gamma}\). El número de componentes \(k\) se elige usando la varianza explicada acumulada o validación cruzada.
Experimentos con Python #
Evaluamos la regresión PCR en el conjunto de datos de diabetes variando el número de componentes y midiendo el desempeño con validación cruzada.
| |
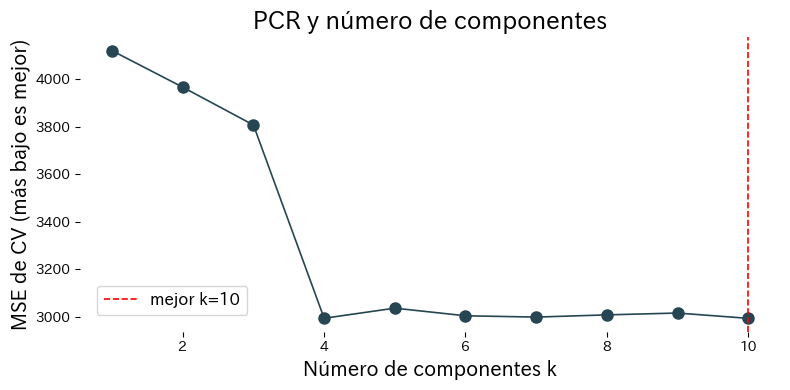
Interpretación de los resultados #
- Al aumentar los componentes, el ajuste sobre el entrenamiento mejora, pero el MSE de validación cruzada alcanza un mínimo intermedio.
- La proporción de varianza explicada indica cuánta variabilidad captura cada componente.
- Analizar los loadings muestra qué características originales contribuyen más a cada dirección principal.
Referencias #
- Jolliffe, I. T. (2002). Principal Component Analysis (2nd ed.). Springer.
- Massy, W. F. (1965). Principal Components Regression in Exploratory Statistical Research. Journal of the American Statistical Association, 60(309), 234–256.