2.1.11
Mínimos cuadrados ponderados (WLS)
Resumen
- WLS asigna pesos específicos a cada observación para que las mediciones confiables tengan mayor influencia en la recta ajustada.
- Al multiplicar el error cuadrado por los pesos se atenúan las observaciones de alta varianza y se mantiene el ajuste cercano a los datos fiables.
- Puede ejecutarse con
LinearRegressionde scikit-learn simplemente proporcionandosample_weight. - Los pesos pueden provenir de varianzas conocidas, diagnósticos de residuos o conocimiento del dominio; diseñarlos con cuidado es fundamental.
Intuicion #
Este metodo se entiende mejor al conectar sus supuestos con la estructura de los datos y su efecto en la generalizacion.
Explicacion Detallada #
Formulación matemática #
Con pesos positivos \(w_i\) minimizamos
$$ L(\boldsymbol\beta, b) = \sum_{i=1}^{n} w_i \left(y_i - (\boldsymbol\beta^\top \mathbf{x}_i + b)\right)^2. $$La elección ideal es \(w_i \propto 1/\sigma_i^2\) (el inverso de la varianza), de modo que las observaciones más precisas aporten más.
Experimentos con Python #
Comparamos OLS y WLS en datos cuyo nivel de ruido cambia por regiones.
| |
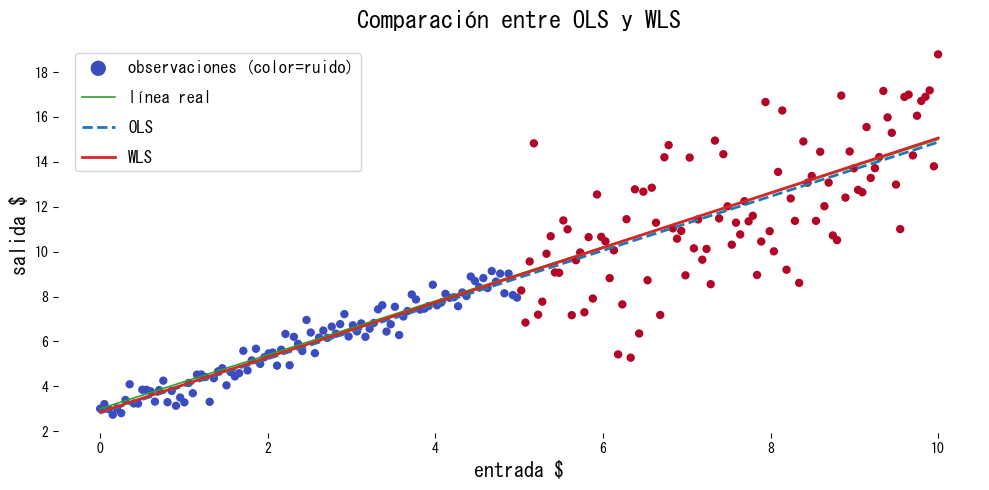
Interpretación de los resultados #
- El uso de pesos inclina el ajuste hacia la región de bajo ruido y produce estimaciones cercanas a la recta verdadera.
- OLS queda sesgado por la zona ruidosa y subestima la pendiente.
- El rendimiento depende de elegir pesos adecuados; los diagnósticos y el conocimiento del dominio son claves.
Referencias #
- Carroll, R. J., & Ruppert, D. (1988). Transformation and Weighting in Regression. Chapman & Hall.
- Seber, G. A. F., & Lee, A. J. (2012). Linear Regression Analysis (2nd ed.). Wiley.