4.3.1
Accuracy
- Exactitud (Accuracy) | Fundamentos y riesgos en Python 3.13の概要を押さえ、評価対象と読み取り方を整理します。
- Python 3.13 のコード例で算出・可視化し、手順と実務での確認ポイントを確認します。
- 図表や補助指標を組み合わせ、モデル比較や閾値調整に活かすヒントをまとめます。
1. Definición #
A partir de la matriz de confusión (verdaderos positivos TP, falsos positivos FP, falsos negativos FN, verdaderos negativos TN) la exactitud se define como:
$$ \mathrm{Accuracy} = \frac{TP + TN}{TP + TN + FP + FN} $$Indica qué proporción total se clasifica correctamente, pero no revela el comportamiento frente a clases minoritarias.
2. Implementación y visualización con Python 3.13 #
Verifica el intérprete e instala las dependencias:
| |
El siguiente script entrena un Random Forest sobre el conjunto Breast Cancer, calcula Accuracy y Balanced Accuracy y muestra ambas métricas en un gráfico de barras. El uso de Pipeline + StandardScaler deja el flujo reproducible. Las imágenes se guardan en static/images/eval/... y pueden regenerarse con generate_eval_assets.py.
| |
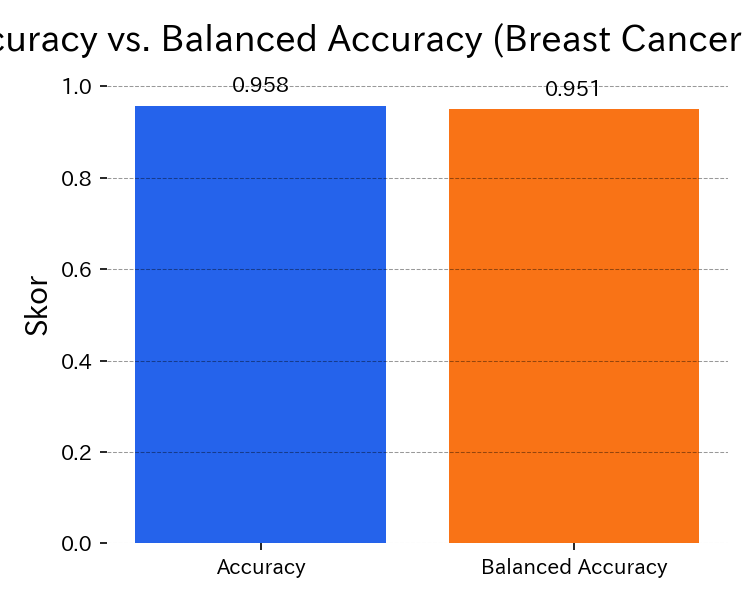
Balanced Accuracy pone en evidencia los fallos cuando hay clases desbalanceadas.
3. Qué hacer ante clases desbalanceadas #
Accuracy ignora el costo relativo de los falsos negativos y falsos positivos. Para tener una visión completa:
- Precision / Recall / F1: cuantifican las falsas alarmas y las omisiones.
- Balanced Accuracy: promedia el recall de cada clase, haciendo visibles las minoritarias.
- Matriz de confusión: indica en qué clases se concentran los errores.
- Curvas ROC-AUC / PR: muestran cómo cambian las métricas al ajustar el umbral de decisión. Balanced Accuracy equivale al promedio de los recalls por clase y suele adoptarse como métrica principal cuando el costo de perder casos minoritarios es alto.
4. Lista de comprobación operativa #
¿Coincide con el costo de negocio? Revisa la matriz de confusión: una “exactitud del 99 %” puede ocultar que nunca se detectan los eventos realmente críticos.
¿Hay margen al ajustar el umbral? Analiza ROC-AUC o PR para ver cómo evolucionaría Accuracy si cambias el umbral.
Reporta múltiples métricas: comparte Precision, Recall, F1 y Balanced Accuracy junto con Accuracy para exponer el equilibrio de errores.
Cuaderno reproducible: mantén un notebook en Python 3.13 que permita repetir la evaluación tras cada retraining.
Resumen #
- Accuracy es un buen titular, pero engañoso cuando las clases están desbalanceadas.
- Un pipeline con escalamientos en Python 3.13 facilita la reproducción del cálculo.
- Combínala con Balanced Accuracy y métricas por clase para tomar decisiones fundamentadas.