4.3.0
Matriz de confusión
- Matriz de confusión | Cómo interpretar el rendimiento de un clasificadorの概要を押さえ、評価対象と読み取り方を整理します。
- Python 3.13 のコード例で算出・可視化し、手順と実務での確認ポイントを確認します。
- 図表や補助指標を組み合わせ、モデル比較や閾値調整に活かすヒントをまとめます。
1. Anatomía de la matriz de confusión #
En un problema binario la matriz tiene forma de tabla 2×2:
| Predicción: Negativa | Predicción: Positiva | |
|---|---|---|
| Real: Negativa | Verdadero negativo (TN) | Falso positivo (FP) |
| Real: Positiva | Falso negativo (FN) | Verdadero positivo (TP) |
- Las filas representan la verdad terreno y las columnas las predicciones del modelo.
- Revisar TP / FP / FN / TN ayuda a ver si el modelo favorece una clase sobre otra.
2. Ejemplo completo con Python 3.13 #
Confirma que trabajas con Python 3.13 e instala las dependencias:
| |
El siguiente script entrena una regresión logística sobre el conjunto Breast Cancer, imprime la matriz y la muestra como mapa de calor. La Pipeline con StandardScaler evita problemas de convergencia y estabiliza el entrenamiento.
| |
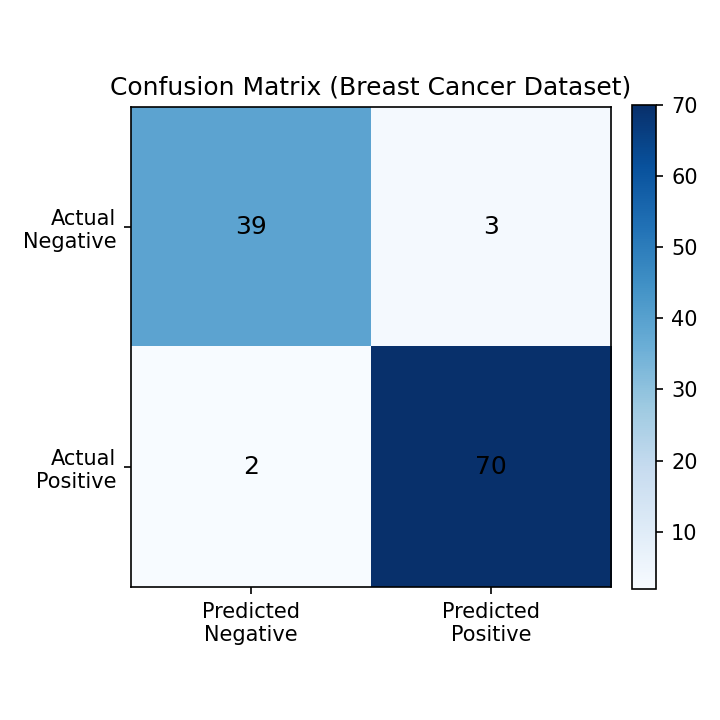
Matriz de confusión generada con scikit-learn en Python 3.13
3. Normalizar para comparar proporciones #
Si existen clases desbalanceadas, conviene normalizar por filas para observar tasas de error.
| |
normalize="true": proporción dentro de cada clase realnormalize="pred": proporción dentro de cada clase predichanormalize="all": proporción sobre todas las observaciones
4. Extensión a múltiples clases #
ConfusionMatrixDisplay.from_predictions construye y etiqueta automáticamente la matriz en tareas multiclase.
| |
5. Puntos de control en proyectos reales #
- Falsos negativos vs. falsos positivos: decide qué error es más costoso (ej. salud, fraude) y vigila esos valores.
- Apóyate en mapas de calor: facilitan identificar clases con sesgo y comunicar hallazgos al resto del equipo.
- Métricas derivadas: obtén precisión, exhaustividad y F1 a partir de la matriz, y compáralas con ROC-AUC o curvas PR para obtener una visión completa.
- Notebooks reproducibles: guardar el flujo en un cuaderno de Python 3.13 acelera los ciclos de ajuste y reentrenamiento.
Resumen #
La matriz de confusión resume TP / FP / FN / TN y visibiliza los sesgos del clasificador.
La normalización revela tasas de error cuando hay clases desbalanceadas.
Combínala con métricas derivadas y con los requisitos del negocio para definir criterios de evaluación accionables.