4.3.4
Log Loss
Resumen
- Log Loss | Medir la calidad de las probabilidadesの概要を押さえ、評価対象と読み取り方を整理します。
- Python 3.13 のコード例で算出・可視化し、手順と実務での確認ポイントを確認します。
- 図表や補助指標を組み合わせ、モデル比較や閾値調整に活かすヒントをまとめます。
1. Definición #
Para una clasificación binaria se expresa como \mathrm{LogLoss} = -\frac{1}{n} \sum_{i=1}^{n} \left[y_i \log(p_i) + (1 - y_i) \log(1 - p_i)\right], donde \(p_i\) es la probabilidad predicha para la clase positiva y \(y_i\) es la etiqueta real (0 o 1). En multiclase se extiende sumando las probabilidades de cada clase con su etiqueta one-hot.
2. Cálculo en Python 3.13 #
| |
| |
Basta pasar el array de probabilidades a log_loss.
3. Curvas de penalización #
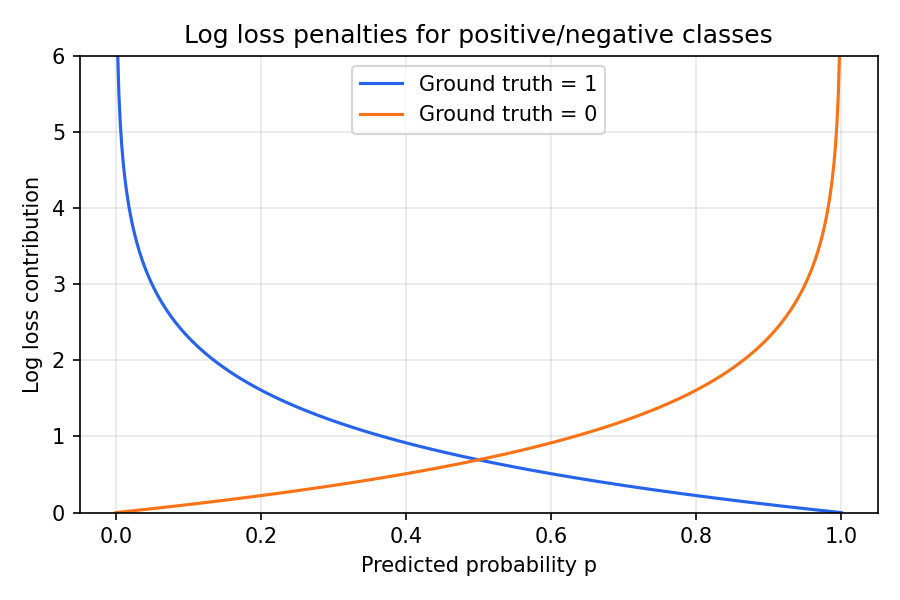
Las probabilidades cercanas a la clase incorrecta generan un coste muy alto.
- Otorgar poca probabilidad a un positivo real (p. ej. 0.1) resulta en una penalización enorme.
- Predecir 0.5 sistemáticamente también se castiga: el modelo no está aprendiendo nada útil.
4. Cuándo usar Log Loss #
- Comprobar la calibración – después de aplicar Platt scaling o isotonic regression, verifica que el Log Loss disminuya.
- Competencias y comparativas – en plataformas como Kaggle el Log Loss es un criterio habitual.
- Comparación independiente del umbral – a diferencia de la exactitud, evalúa toda la distribución de probabilidades. log_loss permite configurar parámetros como labels, eps y ormalize para controlar estabilidad numérica y soportes incompletos.
Resumen #
- Log Loss mide cuánto se apartan las probabilidades del resultado real; cuanto menor, mejor.
- Con scikit-learn en Python 3.13 basta con predict_proba y log_loss.
- Complementa la evaluación con métricas como ROC-AUC o las curvas PR para analizar discriminación y calibración.