4.1.5
Curva de aprendizaje
Resumen
- Una curva de aprendizaje muestra las puntuaciones de entrenamiento y validación a medida que crece el tamaño del conjunto de entrenamiento.
- Usa
learning_curvepara dibujar ambas curvas, evaluar el sesgo/varianza y decidir si más datos ayudarán. - Aplica las conclusiones a la recolección de datos, la capacidad del modelo y la ingeniería de características.
1. ¿Qué es una curva de aprendizaje? #
Registra puntuación de entrenamiento y puntuación de validación mientras se incrementa progresivamente el número de muestras usadas para entrenar. Sirve para responder:
- ¿El modelo sufre de alto sesgo (underfitting) o de alta varianza (overfitting)?
- ¿Aumentar el dataset mejoraría de forma significativa el rendimiento?
- ¿Conviene ajustar hiperparámetros o cambiar la arquitectura del modelo?
2. Ejemplo en Python (regresión Ridge) #
| |
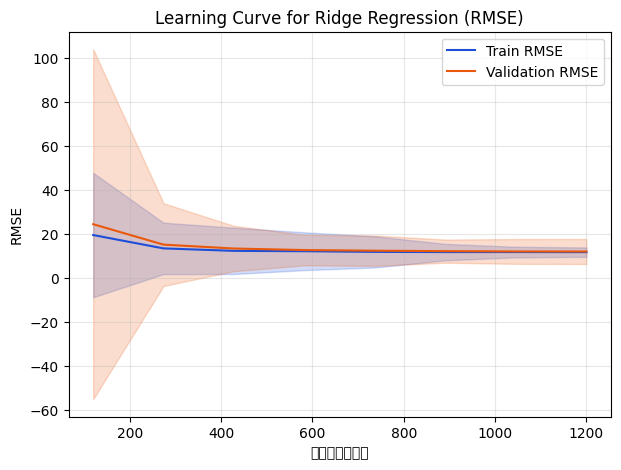
Al aumentar las muestras, la RMSE de entrenamiento empeora y se acerca a la de validación, que mejora y se estabiliza. Cuando ambas convergen, añadir datos tiene un retorno decreciente.
3. Interpretación #
- Alta varianza / sobreajuste: la curva de entrenamiento es excelente y la de validación queda atrás. Refuerza la regularización, reduce características o suma más datos.
- Alto sesgo / infraajuste: ambas curvas son altas (mal rendimiento). Cambia a un modelo más expresivo, ingenia nuevas variables o suaviza la regularización.
- Curvas convergentes: los valores se acercan; más datos apenas mueven la aguja y es mejor replantear modelo o features.
4. Aplicaciones prácticas #
- ROI de la recolección: si la curva de validación sigue mejorando, más datos son valiosos; si se estabiliza, prioriza otras tareas.
- Capacidad del modelo y regularización: analiza la curva antes de ajustar profundidad, ancho o intensidad de regularización.
- Ingeniería de características: si ambas curvas se mantienen altas y paralelas, indica que necesitas mejores atributos.
- Complemento con otras diagnósticas: combínala con curvas de validación o análisis temporal para planificar ciclos de iteración.
Conclusiones #
- Las curvas de aprendizaje desvelan el balance entre overfitting y underfitting y cuantifican el efecto del tamaño de entrenamiento.
- Con
learning_curvees sencillo generarlas y decidir sobre adquisición de datos o cadencia de tuning. - Úsalas junto a otras herramientas de diagnóstico para equilibrar datos, complejidad y objetivos de negocio.