4.1.2
Validación cruzada estratificada
Resumen
- Stratified k-fold mantiene la proporción de clases en cada pliegue, indispensable en datasets desbalanceados.
- Compara la variante estratificada con k-fold estándar para visualizar las diferencias de sesgo.
- Recoge recomendaciones para casos de desequilibrio extremo y cómo interpretar los resultados en la práctica.
| |
Construcción del modelo y validación cruzada #
Dataset de experimentación #
| |
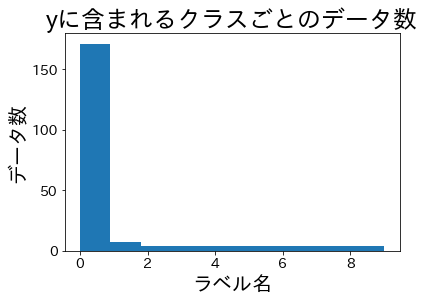
Proporciones tras el split #
Dividimos los datos y comprobamos las proporciones de clase en los conjuntos de entrenamiento y validación.
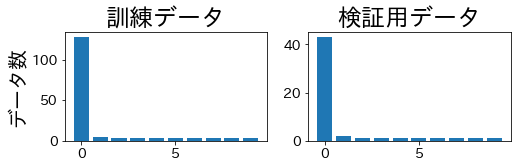
StratifiedKFold #
La proporción de clases se mantiene estable en entrenamiento y validación.
| |
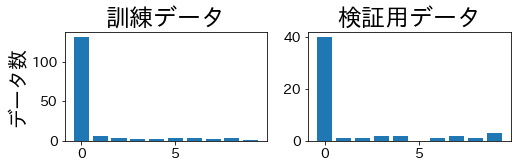
KFold #
K-fold estándar puede generar pliegues que carecen por completo de algunas clases minoritarias.
| |
Consideraciones prácticas #
- Desequilibrio extremo: cuando las clases minoritarias apenas tienen muestras, combina estratificación con validación cruzada repetida para reducir la varianza.
- Regresión: discretiza el objetivo en bins y aplica
StratifiedKFoldsi necesitas pliegues equilibrados. - Política de mezclado: activa
shuffle=True(con semilla fija) cuando el dataset tiene orden temporal o por grupos que puedan sesgar los pliegues.
Stratified k-fold es un reemplazo directo de k-fold cuando importa el balance de clases. Produce divisiones de validación más justas, estabiliza métricas como ROC-AUC y mejora la comparabilidad entre modelos entrenados sobre datos desbalanceados.