4.1.3
Curva de validación
Resumen
- Las curvas de validación muestran cómo cambian las métricas de entrenamiento y validación al variar un hiperparámetro.
- Utiliza
validation_curvepara barrer el coeficiente de regularización, graficar ambas curvas y localizar el punto óptimo. - Aprende a leer la gráfica durante el tuning y qué precauciones conviene tener en cuenta.
1. ¿Qué es una curva de validación? #
Representa en el eje X un hiperparámetro y en el eje Y las puntuaciones de entrenamiento y validación. Interpretación típica:
- Entrenamiento alto, validación baja → sobreajuste; incrementa la regularización o reduce la complejidad.
- Ambos bajos → infraajuste; relaja la regularización o emplea un modelo más expresivo.
- Ambos altos y cercanos → configuración prometedora; confirma con otras métricas.
Mientras que una curva de aprendizaje analiza “tamaño de muestra vs. puntuación”, la curva de validación estudia “hiperparámetro vs. puntuación”.
2. Ejemplo en Python (SVC con C)
#
| |
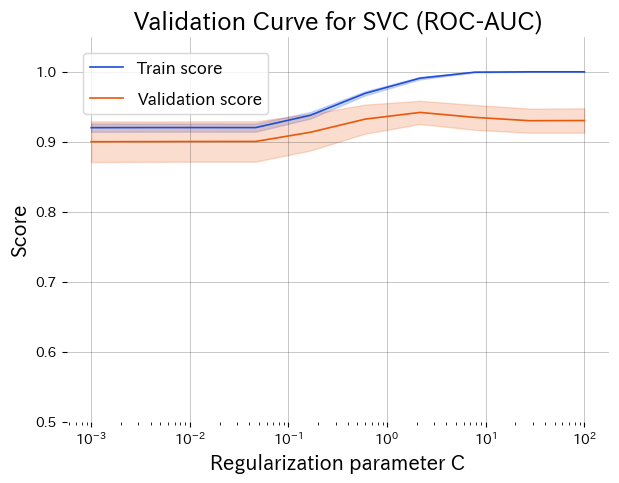
Valores bajos de C producen infraajuste; valores altos generan sobreajuste. Alrededor de C ≈ 1 se alcanza el mejor equilibrio.
3. Cómo leer la gráfica #
- Parte izquierda (C pequeño): regularización fuerte → infraajuste, ambas curvas bajas.
- Parte derecha (C grande): regularización débil → la curva de entrenamiento sube y la de validación cae.
- Pico central: las curvas convergen y alcanzan su máximo; candidatos a valor óptimo.
4. Uso práctico #
- Exploración previa: delimita un rango razonable antes de lanzar búsquedas costosas (grid, random, bayesiana).
- Revisa la varianza: atiende a las bandas sombreadas (desviación típica), sobre todo con pocos datos.
- Prioriza hiperparámetros: genera curvas para los parámetros clave y decide cuáles merecen tuning exhaustivo.
- Combínalas con curvas de aprendizaje: entiende qué hiperparámetro funciona y si conviene recolectar más datos.
Las curvas de validación aportan intuición sobre la dirección del ajuste y facilitan explicar decisiones al resto del equipo. Guardar estos gráficos por modelo simplifica la discusión de mejoras futuras.