Coeficiente de Determinaciónの概要を押さえ、評価対象と読み取り方を整理します。
Python 3.13 のコード例で算出・可視化し、手順と実務での確認ポイントを確認します。
図表や補助指標を組み合わせ、モデル比較や閾値調整に活かすヒントをまとめます。
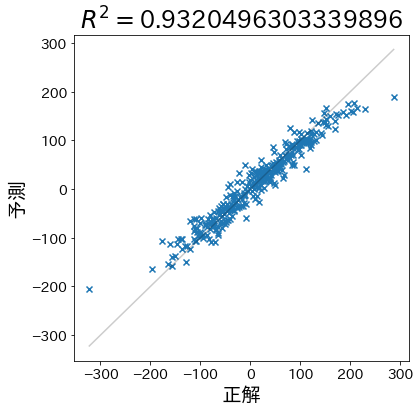
El coeficiente de determinación (en inglés: coefficient of determination, R2) es una métrica estadística que mide qué tan bien las variables independientes (variables explicativas) explican la variabilidad de la variable dependiente (variable objetivo). También se le conoce como tasa de contribución. Fuente:
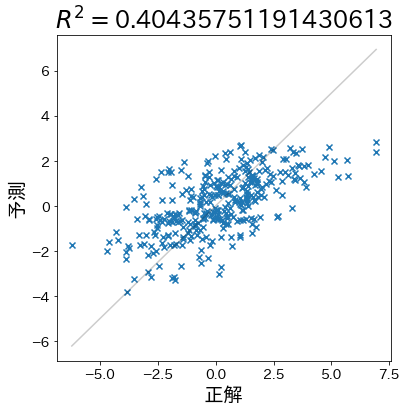
Crearemos un conjunto de datos donde la relación entre las variables independientes y la variable dependiente sea más débil. Esto debería resultar en un coeficiente de determinación (R²) más bajo, reflejando una menor capacidad predictiva del modelo.
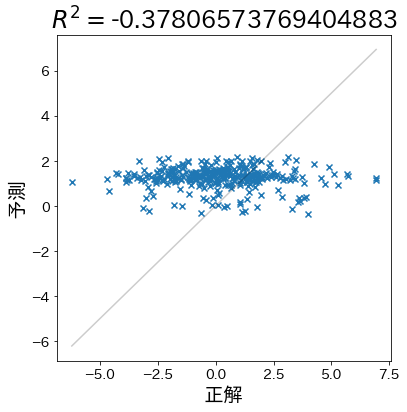
Cuando las predicciones son completamente aleatorias
#
Si las predicciones son peores que simplemente predecir el promedio de los valores reales, el coeficiente de determinación (R²) puede tomar valores negativos. Esto indica que el modelo no es útil para capturar la relación entre las variables.
X,y=make_regression(n_samples=1000,n_informative=3,n_features=20,effective_rank=4,noise=1.5,random_state=RND,)train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.33,random_state=RND)# Reorganizar aleatoriamente train_y y transformar sus valorestrain_y=np.random.permutation(train_y)train_y=np.sin(train_y)*10+1model=RandomForestRegressor(max_depth=1)model.fit(train_X,train_y)pred_y=model.predict(test_X)
Coeficiente de Determinación usando el Método de Mínimos Cuadrados
#
En una regresión lineal simple utilizando el método de mínimos cuadrados, el coeficiente de determinación (R²) siempre se encuentra en el rango de \(0 \le R^2 \le 1\).
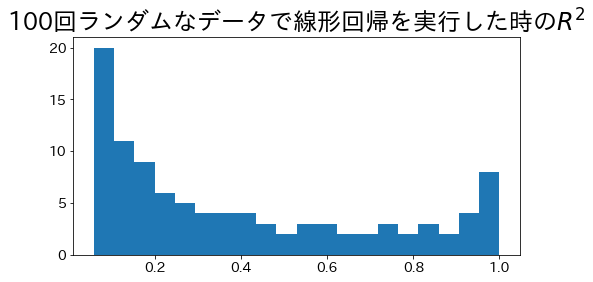
Vamos a añadir ruido aleatorio a los datos y ejecutar la regresión lineal 100 veces para calcular y analizar los valores del coeficiente de determinación.
fromsklearn.linear_modelimportLinearRegressionfromsklearn.pipelineimportmake_pipelinefromsklearn.preprocessingimportStandardScalerfromsklearn.model_selectionimporttrain_test_splitfromsklearn.metricsimportr2_scorefromsklearn.datasetsimportmake_regressionimportmatplotlib.pyplotasplt# Configuración inicialRND=42# Semilla para reproducibilidadr2_scores=[]foriinrange(100):# Crear datos con ruido incrementalX,y=make_regression(n_samples=500,n_informative=1,n_features=1,effective_rank=4,noise=i*0.1,random_state=RND,)train_X,test_X,train_y,test_y=train_test_split(X,y,test_size=0.33,random_state=RND)# Modelo de regresión linealmodel=make_pipeline(StandardScaler(with_mean=False),LinearRegression(positive=True)).fit(train_X,train_y)# Calcular el coeficiente de determinaciónpred_y=model.predict(test_X)r2=r2_score(test_y,pred_y)r2_scores.append(r2)# Visualizar la distribución de los valores R²plt.figure(figsize=(8,4))plt.title("Distribución de $R^2$ en 100 regresiones lineales con datos aleatorios")plt.hist(r2_scores,bins=20)plt.xlabel("$R^2$")plt.ylabel("Frecuencia")plt.show()